diff --git a/tutorials/tutorial1/tutorial.ipynb b/tutorials/tutorial1/tutorial.ipynb
index d48c486b0..3239206d4 100644
--- a/tutorials/tutorial1/tutorial.ipynb
+++ b/tutorials/tutorial1/tutorial.ipynb
@@ -205,7 +205,9 @@
"source": [
"for location in problem.discretised_domains:\n",
" coords = (\n",
- " problem.discretised_domains[location].extract(problem.spatial_variables).flatten()\n",
+ " problem.discretised_domains[location]\n",
+ " .extract(problem.spatial_variables)\n",
+ " .flatten()\n",
" )\n",
" plt.scatter(coords, torch.zeros_like(coords), s=10, label=location)\n",
"_ = plt.legend()\n",
@@ -279,7 +281,9 @@
"source": [
"# create the solver object with RAdam Optimizer, notice that Optimizer needs to\n",
"# be wrapped with the pina.optim.TorchOptimizer class\n",
- "solver = PhysicsInformedSingleModelSolver(problem, model, TorchOptimizer(torch.optim.RAdam, lr=0.005))"
+ "solver = PhysicsInformedSingleModelSolver(\n",
+ " problem, model, TorchOptimizer(torch.optim.RAdam, lr=0.005)\n",
+ ")"
]
},
{
diff --git a/tutorials/tutorial1/tutorial.py b/tutorials/tutorial1/tutorial.py
index cdff548f8..7d7dd9b68 100644
--- a/tutorials/tutorial1/tutorial.py
+++ b/tutorials/tutorial1/tutorial.py
@@ -1,15 +1,15 @@
#!/usr/bin/env python
# coding: utf-8
-# # Tutorial: Introductory Tutorial: Physics Informed Neural Networks with PINA
+# # Tutorial: Introductory Tutorial: Physics Informed Neural Networks with PINA
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial1/tutorial.ipynb)
-#
+#
# > ##### ⚠️ ***Before starting:***
# > We assume you are already familiar with the concepts covered in the [Getting started with PINA](https://mathlab.github.io/PINA/_tutorial.html#getting-started-with-pina) tutorials. If not, we strongly recommend reviewing them before exploring this advanced topic.
-#
+#
# In this tutorial, we will demonstrate a typical use case of **PINA** for Physics Informed Neural Network (PINN) training. We will cover the basics of training a PINN with PINA, if you want to go further into PINNs look at our dedicated [tutorials](https://mathlab.github.io/PINA/_tutorial.html#physics-informed-neural-networks) on the topic.
-#
+#
# Let's start by importing the useful modules:
# In[1]:
@@ -43,9 +43,9 @@
# ## Build the problem
-#
+#
# We will use a simple Ordinary Differential Equation as pedagogical example:
-#
+#
# $$
# \begin{equation}
# \begin{cases}
@@ -54,9 +54,9 @@
# \end{cases}
# \end{equation}
# $$
-#
-# with the analytical solution $u(x) = e^x$.
-#
+#
+# with the analytical solution $u(x) = e^x$.
+#
# The PINA problem is easly written as:
# In[2]:
@@ -100,8 +100,8 @@ def solution(self, pts):
problem.discretise_domain(20, "lh", domains=["D"])
-# ## Generate data
-#
+# ## Generate data
+#
# Data for training can come in form of direct numerical simulation results, or points in the domains. In case we perform unsupervised learning, we just need the collocation points for training, i.e. points where we want to evaluate the neural network. Sampling point in **PINA** is very easy, here we show three examples using the `.discretise_domain` method of the `AbstractProblem` class.
# In[4]:
@@ -144,18 +144,18 @@ def solution(self, pts):
# ## Easily solve a Physics Problem with three step pipeline
# Once the problem is defined and the data is generated, we can move on to modeling. This process consists of three key steps:
-#
+#
# **Choosing a Model**
# - Select a neural network architecture. You can use the model we provide in the `pina.model` module (see [here](https://mathlab.github.io/PINA/_rst/_code.html#models) for a full list), or define a custom PyTorch module (more on this [here](https://pytorch.org/docs/stable/notes/modules.html)).
-#
+#
# **Choosing a PINN Solver & Defining the Trainer**
# * Use a Physics Informed solver from `pina.solver` module to solve the problem using the specified model. We have already implemented most State-Of-The-Arte solvers for you, [have a look](https://mathlab.github.io/PINA/_rst/_code.html#solvers) if interested. Today we will use the standard `PINN` solver.
-#
+#
# **Training**
# * Train the model with the [`Trainer`](https://mathlab.github.io/PINA/_rst/trainer.html) class. The Trainer class provides powerful features to enhance model accuracy, optimize training time and memory, and simplify logging and visualization, thanks to PyTorch Lightning's excellent work, see [our dedicated tutorial](https://mathlab.github.io/PINA/tutorial11/tutorial.html) for further details. By default, training metrics (e.g., MSE error) are logged using a lightning logger (CSVLogger). If you prefer manual tracking, use `pina.callback.MetricTracker`.
-#
+#
# Let's cover all steps one by one!
-#
+#
# First we build the model, in this case a FeedForward neural network, with two layers of size 10 and hyperbolic tangent activation:
# In[7]:
@@ -171,7 +171,7 @@ def solution(self, pts):
# Then we build the solver. The Physics-Informed Neural Network (`PINN`) solver class needs to be initialised with a `model` and a specific `problem` to be solved. They also take extra arguments, as the optimizer, scheduler, loss type and weighting for the different conditions which are all set to their defualt values.
-#
+#
# >##### 💡***Bonus tip:***
# > All physics solvers in PINA can handle both forward and inverse problems without requiring any changes to the model or solver structure! See [our tutorial](https://mathlab.github.io/PINA/tutorial7/tutorial.html) of inverse problems for more infos.
@@ -184,10 +184,10 @@ def solution(self, pts):
# Finally, we train the model using the Trainer API. The trainer offers various options to customize your training, refer to the official documentation for details. Here, we highlight the `MetricTracker` from `pina.callback`, which helps track metrics during training. In order to train just call the `.train()` method.
-#
+#
# > ##### ⚠️ ***Important Note:***
# > In PINA you can log metrics in different ways. The simplest approach is to use the `MetricTraker` class from `pina.callbacks` as we will see today. However, expecially when we need to train multiple times to get an average of the loss across multiple runs, we suggest to use `lightning.pytorch.loggers` (see [here](https://lightning.ai/docs/pytorch/stable/extensions/logging.html) for reference).
-#
+#
# In[ ]:
@@ -218,7 +218,7 @@ def solution(self, pts):
trainer.logged_metrics
-# By using `matplotlib` we can also do some qualitative plots of the solution.
+# By using `matplotlib` we can also do some qualitative plots of the solution.
# In[11]:
@@ -249,17 +249,17 @@ def solution(self, pts):
# ## What's Next?
-#
+#
# Congratulations on completing the introductory tutorial on Physics-Informed Training! Now that you have a solid foundation, here are several exciting directions you can explore:
-#
+#
# 1. **Experiment with Training Duration & Network Architecture**: Try different training durations and tweak the network architecture to optimize performance.
-#
+#
# 2. **Explore Other Models in `pina.model`**: Check out other models available in `pina.model` or design your own custom PyTorch module to suit your needs.
-#
+#
# 3. **Run Training on a GPU**: Speed up your training by running on a GPU and compare the performance improvements.
-#
+#
# 4. **Test Various Solvers**: Explore and evaluate different solvers to assess their performance on various types of problems.
-#
+#
# 5. **... and many more!**: The possibilities are vast! Continue experimenting with advanced configurations, solvers, and other features in PINA.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial10/tutorial.py b/tutorials/tutorial10/tutorial.py
index 48f759bb1..4c4acb597 100644
--- a/tutorials/tutorial10/tutorial.py
+++ b/tutorials/tutorial10/tutorial.py
@@ -2,12 +2,12 @@
# coding: utf-8
# # Tutorial: Solving the Kuramoto–Sivashinsky Equation with Averaging Neural Operator
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial10/tutorial.ipynb)
-#
-#
+#
+#
# In this tutorial, we will build a Neural Operator using the **`AveragingNeuralOperator`** model and the **`SupervisedSolver`**. By the end of this tutorial, you will be able to train a Neural Operator to learn the operator for time-dependent PDEs.
-#
+#
# Let's start by importing the necessary modules.
# In[1]:
@@ -24,8 +24,12 @@
get_ipython().system('pip install "pina-mathlab[tutorial]"')
# get the data
get_ipython().system('mkdir "data"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial10/data/Data_KS.mat" -O "data/Data_KS.mat"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial10/data/Data_KS2.mat" -O "data/Data_KS2.mat"')
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial10/data/Data_KS.mat" -O "data/Data_KS.mat"'
+ )
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial10/data/Data_KS2.mat" -O "data/Data_KS2.mat"'
+ )
import torch
import matplotlib.pyplot as plt
@@ -41,36 +45,36 @@
# ## Data Generation
-#
+#
# In this tutorial, we will focus on solving the **Kuramoto-Sivashinsky (KS)** equation, a fourth-order nonlinear PDE. The equation is given by:
-#
+#
# $$
# \frac{\partial u}{\partial t}(x,t) = -u(x,t)\frac{\partial u}{\partial x}(x,t) - \frac{\partial^{4}u}{\partial x^{4}}(x,t) - \frac{\partial^{2}u}{\partial x^{2}}(x,t).
# $$
-#
+#
# In this equation, $x \in \Omega = [0, 64]$ represents a spatial location, and $t \in \mathbb{T} = [0, 50]$ represents time. The function $u(x, t)$ is the value of the function at each point in space and time, with $u(x, t) \in \mathbb{R}$. We denote the solution space as $\mathbb{U}$, where $u \in \mathbb{U}$.
-#
+#
# We impose Dirichlet boundary conditions on the derivative of $u$ at the boundary of the domain $\partial \Omega$:
-#
+#
# $$
# \frac{\partial u}{\partial x}(x,t) = 0 \quad \forall (x,t) \in \partial \Omega \times \mathbb{T}.
# $$
-#
+#
# The initial conditions are sampled from a distribution over truncated Fourier series with random coefficients $\{A_k, \ell_k, \phi_k\}_k$, as follows:
-#
+#
# $$
# u(x,0) = \sum_{k=1}^N A_k \sin\left(2 \pi \frac{\ell_k x}{L} + \phi_k\right),
# $$
-#
+#
# where:
# - $A_k \in [-0.4, -0.3]$,
# - $\ell_k = 2$,
# - $\phi_k = 2\pi \quad \forall k=1,\dots,N$.
-#
-# We have already generated data for different initial conditions. The goal is to build a Neural Operator that, given $u(x,t)$, outputs $u(x,t+\delta)$, where $\delta$ is a fixed time step.
-#
+#
+# We have already generated data for different initial conditions. The goal is to build a Neural Operator that, given $u(x,t)$, outputs $u(x,t+\delta)$, where $\delta$ is a fixed time step.
+#
# We will cover the Neural Operator architecture later, but for now, let’s start by importing the data.
-#
+#
# **Note:**
# The numerical integration is obtained using a pseudospectral method for spatial derivative discretization and implicit Runge-Kutta 5 for temporal dynamics.
@@ -102,7 +106,7 @@
# - `B` is the batch size (i.e., how many initial conditions we sample),
# - `N` is the number of points in the mesh (which is the product of the discretization in $x$ times the one in $t$),
# - `D` is the dimension of the problem (in this case, we have three variables: $[u, t, x]$).
-#
+#
# We are now going to plot some trajectories!
# In[3]:
@@ -166,36 +170,36 @@ def plot_trajectory(coords, real, no_sol=None):
# As we can see, as time progresses, the solution becomes chaotic, making it very difficult to learn! We will now focus on building a Neural Operator using the `SupervisedSolver` class to tackle this problem.
-#
+#
# ## Averaging Neural Operator
-#
+#
# We will build a neural operator $\texttt{NO}$, which takes the solution at time $t=0$ for any $x\in\Omega$, the time $t$ at which we want to compute the solution, and gives back the solution to the KS equation $u(x, t)$. Mathematically:
-#
+#
# $$
# \texttt{NO}_\theta : \mathbb{U} \rightarrow \mathbb{U},
# $$
-#
+#
# such that
-#
+#
# $$
# \texttt{NO}_\theta[u(t=0)](x, t) \rightarrow u(x, t).
# $$
-#
+#
# There are many ways to approximate the following operator, for example, by using a 2D [FNO](https://mathlab.github.io/PINA/_rst/model/fourier_neural_operator.html) (for regular meshes), a [DeepOnet](https://mathlab.github.io/PINA/_rst/model/deeponet.html), [Continuous Convolutional Neural Operator](https://mathlab.github.io/PINA/_rst/model/block/convolution.html), or [MIONet](https://mathlab.github.io/PINA/_rst/model/mionet.html). In this tutorial, we will use the *Averaging Neural Operator* presented in [*The Nonlocal Neural Operator: Universal Approximation*](https://arxiv.org/abs/2304.13221), which is a [Kernel Neural Operator](https://mathlab.github.io/PINA/_rst/model/kernel_neural_operator.html) with an integral kernel:
-#
+#
# $$
# K(v) = \sigma\left(Wv(x) + b + \frac{1}{|\Omega|}\int_\Omega v(y)dy\right)
# $$
-#
+#
# where:
-#
+#
# * $v(x) \in \mathbb{R}^{\rm{emb}}$ is the update for a function $v$, with $\mathbb{R}^{\rm{emb}}$ being the embedding (hidden) size.
# * $\sigma$ is a non-linear activation function.
# * $W \in \mathbb{R}^{\rm{emb} \times \rm{emb}}$ is a tunable matrix.
# * $b \in \mathbb{R}^{\rm{emb}}$ is a tunable bias.
-#
+#
# In PINA, many Kernel Neural Operators are already implemented. The modular components of the [Kernel Neural Operator](https://mathlab.github.io/PINA/_rst/model/kernel_neural_operator.html) class allow you to create new ones by composing base kernel layers.
-#
+#
# **Note:** We will use the already built class `AveragingNeuralOperator`. As a constructive exercise, try to use the [KernelNeuralOperator](https://mathlab.github.io/PINA/_rst/model/kernel_neural_operator.html) class to build a kernel neural operator from scratch. You might employ the different layers that we have in PINA, such as [FeedForward](https://mathlab.github.io/PINA/_rst/model/feed_forward.html) and [AveragingNeuralOperator](https://mathlab.github.io/PINA/_rst/model/average_neural_operator.html) layers.
# In[4]:
@@ -222,9 +226,9 @@ def forward(self, x):
# Super easy! Notice that we use the `SIREN` activation function, which is discussed in more detail in the paper [Implicit Neural Representations with Periodic Activation Functions](https://arxiv.org/abs/2006.09661).
-#
+#
# ## Solving the KS problem
-#
+#
# We will now focus on solving the KS equation using the `SupervisedSolver` class and the `AveragingNeuralOperator` model. As done in the [FNO tutorial](https://github.com/mathLab/PINA/blob/master/tutorials/tutorial5/tutorial.ipynb), we now create the Neural Operator problem class with `SupervisedProblem`.
# In[ ]:
@@ -267,7 +271,7 @@ def forward(self, x):
)
-# As we can see, we can obtain nice results considering the small training time and the difficulty of the problem!
+# As we can see, we can obtain nice results considering the small training time and the difficulty of the problem!
# Let's take a look at the training and testing error:
# In[7]:
@@ -293,13 +297,13 @@ def forward(self, x):
# As we can see, the error is pretty small, which aligns with the observations from the previous plots.
# ## What's Next?
-#
+#
# You have completed the tutorial on solving time-dependent PDEs using Neural Operators in **PINA**. Great job! Here are some potential next steps you can explore:
-#
+#
# 1. **Train the network for longer or with different layer sizes**: Experiment with various configurations, such as adjusting the number of layers or hidden dimensions, to further improve accuracy and observe the impact on performance.
-#
+#
# 2. **Use a more challenging dataset**: Try using the more complex dataset [Data_KS2.mat](dat/Data_KS2.mat) where $A_k \in [-0.5, 0.5]$, $\ell_k \in [1, 2, 3]$, and $\phi_k \in [0, 2\pi]$ for a more difficult task. This dataset may require longer training and testing.
-#
+#
# 3. **... and many more...**: Explore other models, such as the [FNO](https://mathlab.github.io/PINA/_rst/models/fno.html), [DeepOnet](https://mathlab.github.io/PINA/_rst/models/deeponet.html), or implement your own operator using the [KernelNeuralOperator](https://mathlab.github.io/PINA/_rst/models/base_no.html) class to compare performance and find the best model for your task.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial11/tutorial.ipynb b/tutorials/tutorial11/tutorial.ipynb
index d62a273f1..3ae863a2b 100644
--- a/tutorials/tutorial11/tutorial.ipynb
+++ b/tutorials/tutorial11/tutorial.ipynb
@@ -206,7 +206,7 @@
"* Directly calling methods (e.g., on_validation_end) is strongly discouraged.\n",
"* Whenever possible, your callbacks should not depend on the order in which they are executed.\n",
"\n",
- "We will try now to implement a naive version of `MetricTracker` to show how callbacks work. Notice that this is a very easy application of callbacks, fortunately in **PINA** we already provide more advanced callbacks in `pina.callback`."
+ "We will try now to implement a naive version of `MetricTracker` to show how callbacks work. Notice that this is a very easy application of callbacks, fortunately in **PINA** we already provide more advanced callbacks in `pina.callback`."
]
},
{
@@ -225,9 +225,7 @@
" def __init__(self):\n",
" self.saved_metrics = []\n",
"\n",
- " def on_train_epoch_end(\n",
- " self, trainer, __\n",
- " ): \n",
+ " def on_train_epoch_end(self, trainer, __):\n",
" \"\"\"\n",
" Function called at the end of each epoch.\n",
" \"\"\"\n",
diff --git a/tutorials/tutorial11/tutorial.py b/tutorials/tutorial11/tutorial.py
index dd624cced..095e8c665 100644
--- a/tutorials/tutorial11/tutorial.py
+++ b/tutorials/tutorial11/tutorial.py
@@ -3,15 +3,15 @@
# # Tutorial: Introduction to `Trainer` class
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial11/tutorial.ipynb)
-#
-# In this tutorial, we will delve deeper into the functionality of the `Trainer` class, which serves as the cornerstone for training **PINA** [Solvers](https://mathlab.github.io/PINA/_rst/_code.html#solvers).
-#
+#
+# In this tutorial, we will delve deeper into the functionality of the `Trainer` class, which serves as the cornerstone for training **PINA** [Solvers](https://mathlab.github.io/PINA/_rst/_code.html#solvers).
+#
# The `Trainer` class offers a plethora of features aimed at improving model accuracy, reducing training time and memory usage, facilitating logging visualization, and more thanks to the amazing job done by the PyTorch Lightning team!
-#
+#
# Our leading example will revolve around solving a simple regression problem where we want to approximate the following function with a Neural Net model $\mathcal{M}_{\theta}$:
# $$y = x^3$$
# by having only a set of $20$ observations $\{x_i, y_i\}_{i=1}^{20}$, with $x_i \sim\mathcal{U}[-3, 3]\;\;\forall i\in(1,\dots,20)$.
-#
+#
# Let's start by importing useful modules!
# In[1]:
@@ -70,16 +70,16 @@
# ## Trainer Accelerator
-#
+#
# When creating the `Trainer`, **by default** the most performing `accelerator` for training which is available in your system will be chosen, ranked as follows:
# 1. [TPU](https://cloud.google.com/tpu/docs/intro-to-tpu)
# 2. [IPU](https://www.graphcore.ai/products/ipu)
# 3. [HPU](https://habana.ai/)
# 4. [GPU](https://www.intel.com/content/www/us/en/products/docs/processors/what-is-a-gpu.html#:~:text=What%20does%20GPU%20stand%20for,video%20editing%2C%20and%20gaming%20applications) or [MPS](https://developer.apple.com/metal/pytorch/)
# 5. CPU
-#
+#
# For setting manually the `accelerator` run:
-#
+#
# * `accelerator = {'gpu', 'cpu', 'hpu', 'mps', 'cpu', 'ipu'}` sets the accelerator to a specific one
# In[ ]:
@@ -91,11 +91,11 @@
# As you can see, even if a `GPU` is available on the system, it is not used since we set `accelerator='cpu'`.
# ## Trainer Logging
-#
+#
# In **PINA** you can log metrics in different ways. The simplest approach is to use the `MetricTracker` class from `pina.callbacks`, as seen in the [*Introduction to Physics Informed Neural Networks training*](https://github.com/mathLab/PINA/blob/master/tutorials/tutorial1/tutorial.ipynb) tutorial.
-#
+#
# However, especially when we need to train multiple times to get an average of the loss across multiple runs, `lightning.pytorch.loggers` might be useful. Here we will use `TensorBoardLogger` (more on [logging](https://lightning.ai/docs/pytorch/stable/extensions/logging.html) here), but you can choose the one you prefer (or make your own one).
-#
+#
# We will now import `TensorBoardLogger`, do three runs of training, and then visualize the results. Notice we set `enable_model_summary=False` to avoid model summary specifications (e.g. number of parameters); set it to `True` if needed.
# In[ ]:
@@ -133,21 +133,21 @@
#
# As you can see, by default, **PINA** logs the losses which are shown in the progress bar, as well as the number of epochs. You can always insert more loggings by either defining a **callback** ([more on callbacks](https://lightning.ai/docs/pytorch/stable/extensions/callbacks.html)), or inheriting the solver and modifying the programs with different **hooks** ([more on hooks](https://lightning.ai/docs/pytorch/stable/common/lightning_module.html#hooks)).
-#
+#
# ## Trainer Callbacks
-#
+#
# Whenever we need to access certain steps of the training for logging, perform static modifications (i.e. not changing the `Solver`), or update `Problem` hyperparameters (static variables), we can use **Callbacks**. Notice that **Callbacks** allow you to add arbitrary self-contained programs to your training. At specific points during the flow of execution (hooks), the Callback interface allows you to design programs that encapsulate a full set of functionality. It de-couples functionality that does not need to be in **PINA** `Solver`s.
-#
+#
# Lightning has a callback system to execute them when needed. **Callbacks** should capture NON-ESSENTIAL logic that is NOT required for your lightning module to run.
-#
+#
# The following are best practices when using/designing callbacks:
-#
+#
# * Callbacks should be isolated in their functionality.
# * Your callback should not rely on the behavior of other callbacks in order to work properly.
# * Do not manually call methods from the callback.
# * Directly calling methods (e.g., on_validation_end) is strongly discouraged.
# * Whenever possible, your callbacks should not depend on the order in which they are executed.
-#
+#
# We will try now to implement a naive version of `MetricTraker` to show how callbacks work. Notice that this is a very easy application of callbacks, fortunately in **PINA** we already provide more advanced callbacks in `pina.callbacks`.
# In[6]:
@@ -172,7 +172,7 @@ def on_train_epoch_end(
# Let's see the results when applied to the problem. You can define **callbacks** when initializing the `Trainer` by using the `callbacks` argument, which expects a list of callbacks.
-#
+#
# In[ ]:
@@ -206,8 +206,8 @@ def on_train_epoch_end(
trainer.callbacks[0].saved_metrics[:3] # only the first three epochs
-# PyTorch Lightning also has some built-in `Callbacks` which can be used in **PINA**, [here is an extensive list](https://lightning.ai/docs/pytorch/stable/extensions/callbacks.html#built-in-callbacks).
-#
+# PyTorch Lightning also has some built-in `Callbacks` which can be used in **PINA**, [here is an extensive list](https://lightning.ai/docs/pytorch/stable/extensions/callbacks.html#built-in-callbacks).
+#
# We can, for example, try the `EarlyStopping` routine, which automatically stops the training when a specific metric converges (here the `train_loss`). In order to let the training keep going forever, set `max_epochs=-1`.
# In[ ]:
@@ -237,17 +237,17 @@ def on_train_epoch_end(
# As we can see the model automatically stop when the logging metric stopped improving!
# ## Trainer Tips to Boost Accuracy, Save Memory and Speed Up Training
-#
+#
# Until now we have seen how to choose the right `accelerator`, how to log and visualize the results, and how to interface with the program in order to add specific parts of code at specific points via `callbacks`.
# Now, we will focus on how to boost your training by saving memory and speeding it up, while maintaining the same or even better degree of accuracy!
-#
+#
# There are several built-in methods developed in PyTorch Lightning which can be applied straightforward in **PINA**. Here we report some:
-#
+#
# * [Stochastic Weight Averaging](https://pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging/) to boost accuracy
# * [Gradient Clipping](https://deepgram.com/ai-glossary/gradient-clipping) to reduce computational time (and improve accuracy)
# * [Gradient Accumulation](https://lightning.ai/docs/pytorch/stable/common/optimization.html#id3) to save memory consumption
# * [Mixed Precision Training](https://lightning.ai/docs/pytorch/stable/common/optimization.html#id3) to save memory consumption
-#
+#
# We will just demonstrate how to use the first two and see the results compared to standard training.
# We use the [`Timer`](https://lightning.ai/docs/pytorch/stable/api/lightning.pytorch.callbacks.Timer.html#lightning.pytorch.callbacks.Timer) callback from `pytorch_lightning.callbacks` to track the times. Let's start by training a simple model without any optimization (train for 500 epochs).
@@ -312,7 +312,7 @@ def on_train_epoch_end(
# As you can see, the training time does not change at all! Notice that around epoch 350
# the scheduler is switched from the defalut one `ConstantLR` to the Stochastic Weight Average Learning Rate (`SWALR`).
# This is because by default `StochasticWeightAveraging` will be activated after `int(swa_epoch_start * max_epochs)` with `swa_epoch_start=0.7` by default. Finally, the final `train_loss` is lower when `StochasticWeightAveraging` is used.
-#
+#
# We will now do the same but clippling the gradient to be relatively small.
# In[ ]:
@@ -341,18 +341,18 @@ def on_train_epoch_end(
# As we can see, by applying gradient clipping, we were able to achieve even lower error!
-#
+#
# ## What's Next?
-#
+#
# Now you know how to use the `Trainer` class efficiently in **PINA**! There are several directions you can explore next:
-#
+#
# 1. **Explore Training on Different Devices**: Test training times on various devices (e.g., `TPU`) to compare performance.
-#
+#
# 2. **Reduce Memory Costs**: Experiment with mixed precision training and gradient accumulation to optimize memory usage, especially when training Neural Operators.
-#
+#
# 3. **Benchmark `Trainer` Speed**: Benchmark the training speed of the `Trainer` class for different precisions to identify potential optimizations.
-#
+#
# 4. **...and many more!**: Consider expanding to **multi-GPU** setups or other advanced configurations for large-scale training.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
-#
+#
diff --git a/tutorials/tutorial12/tutorial.py b/tutorials/tutorial12/tutorial.py
index 9a551e3a0..8cecb71e8 100644
--- a/tutorials/tutorial12/tutorial.py
+++ b/tutorials/tutorial12/tutorial.py
@@ -50,7 +50,6 @@
from pina.domain import CartesianDomain
from pina.operator import grad, fast_grad, laplacian
-
# Let's begin by defining the Burgers equation and its initial condition as Python functions. These functions will take the model's `input` (spatial and temporal coordinates) and `output` (predicted solution) as arguments. The goal is to compute the residuals for the Burgers equation, which we will minimize during training.
# In[2]:
diff --git a/tutorials/tutorial13/tutorial.ipynb b/tutorials/tutorial13/tutorial.ipynb
index 609ea3946..7c8928110 100644
--- a/tutorials/tutorial13/tutorial.ipynb
+++ b/tutorials/tutorial13/tutorial.ipynb
@@ -36,7 +36,8 @@
"from pina import Condition, Trainer\n",
"from pina.problem import SpatialProblem\n",
"from pina.solver import (\n",
- " PhysicsInformedSingleModelSolver, SelfAdaptivePhysicsInformedSolver\n",
+ " PhysicsInformedSingleModelSolver,\n",
+ " SelfAdaptivePhysicsInformedSolver,\n",
")\n",
"from pina.loss import LpLoss\n",
"from pina.domain import CartesianDomain\n",
diff --git a/tutorials/tutorial13/tutorial.py b/tutorials/tutorial13/tutorial.py
index 71d4bce05..082ecd2ce 100644
--- a/tutorials/tutorial13/tutorial.py
+++ b/tutorials/tutorial13/tutorial.py
@@ -2,13 +2,13 @@
# coding: utf-8
# # Tutorial: Learning Multiscale PDEs Using Fourier Feature Networks
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial13/tutorial.ipynb)
-#
+#
# This tutorial demonstrates how to solve a PDE with multiscale behavior using Physics-Informed Neural Networks (PINNs), as discussed in [*On the Eigenvector Bias of Fourier Feature Networks: From Regression to Solving Multi-Scale PDEs with Physics-Informed Neural Networks*](https://doi.org/10.1016/j.cma.2021.113938).
-#
+#
# Let’s begin by importing the necessary libraries.
-#
+#
# In[1]:
@@ -40,30 +40,30 @@
# ## Multiscale Problem
-#
+#
# We begin by presenting the problem, which is also discussed in Section 2 of [*On the Eigenvector Bias of Fourier Feature Networks: From Regression to Solving Multi-Scale PDEs with Physics-Informed Neural Networks*](https://doi.org/10.1016/j.cma.2021.113938). The one-dimensional Poisson problem we aim to solve is mathematically defined as:
-#
+#
# \begin{equation}
# \begin{cases}
# \Delta u(x) + f(x) = 0 \quad x \in [0,1], \\
# u(x) = 0 \quad x \in \partial[0,1],
# \end{cases}
# \end{equation}
-#
+#
# We define the solution as:
-#
+#
# $$
# u(x) = \sin(2\pi x) + 0.1 \sin(50\pi x),
# $$
-#
+#
# which leads to the corresponding force term:
-#
+#
# $$
# f(x) = (2\pi)^2 \sin(2\pi x) + 0.1 (50 \pi)^2 \sin(50\pi x).
# $$
-#
+#
# While this example is simple and pedagogical, it's important to note that the solution exhibits low-frequency behavior in the macro-scale and high-frequency behavior in the micro-scale. This characteristic is common in many practical scenarios.
-#
+#
# Below is the implementation of the `Poisson` problem as described mathematically above.
# > **👉 We have a dedicated [tutorial](https://mathlab.github.io/PINA/tutorial16/tutorial.html) to teach how to build a Problem from scratch — have a look if you're interested!**
@@ -106,12 +106,12 @@ def solution(self, x):
problem.discretise_domain(2, "grid", domains="boundary")
-# A standard PINN approach would involve fitting the model using a Feed Forward (fully connected) Neural Network. For a conventional fully-connected neural network, it is relatively easy to approximate a function $u$, given sufficient data inside the computational domain.
-#
+# A standard PINN approach would involve fitting the model using a Feed Forward (fully connected) Neural Network. For a conventional fully-connected neural network, it is relatively easy to approximate a function $u$, given sufficient data inside the computational domain.
+#
# However, solving high-frequency or multi-scale problems presents significant challenges to PINNs, especially when the number of data points is insufficient to capture the different scales effectively.
-#
+#
# Below, we run a simulation using both the `PINN` solver and the self-adaptive `SAPINN` solver, employing a [`FeedForward`](https://mathlab.github.io/PINA/_modules/pina/model/feed_forward.html#FeedForward) model.
-#
+#
# In[ ]:
@@ -176,10 +176,10 @@ def plot_solution(pinn_to_use, title):
plot_solution(sapinn, "Self Adaptive PINN solution")
-# We can clearly observe that neither of the two solvers has successfully learned the solution.
-# The issue is not with the optimization strategy (i.e., the solver), but rather with the model used to solve the problem.
+# We can clearly observe that neither of the two solvers has successfully learned the solution.
+# The issue is not with the optimization strategy (i.e., the solver), but rather with the model used to solve the problem.
# A simple `FeedForward` network struggles to handle multiscale problems, especially when there are not enough collocation points to capture the different scales effectively.
-#
+#
# Next, let's compute the $l_2$ relative error for both the `PINN` and `SAPINN` solutions:
# In[5]:
@@ -199,20 +199,20 @@ def plot_solution(pinn_to_use, title):
# Which is indeed very high!
-#
+#
# ## Fourier Feature Embedding in PINA
# Fourier Feature Embedding is a technique used to transform the input features, aiding the network in learning multiscale variations in the output. It was first introduced in [*On the Eigenvector Bias of Fourier Feature Networks: From Regression to Solving Multi-Scale PDEs with Physics-Informed Neural Networks*](https://doi.org/10.1016/j.cma.2021.113938), where it demonstrated excellent results for multiscale problems.
-#
+#
# The core idea behind Fourier Feature Embedding is to map the input $\mathbf{x}$ into an embedding $\tilde{\mathbf{x}}$, defined as:
-#
+#
# $$
# \tilde{\mathbf{x}} = \left[\cos\left( \mathbf{B} \mathbf{x} \right), \sin\left( \mathbf{B} \mathbf{x} \right)\right],
# $$
-#
+#
# where $\mathbf{B}_{ij} \sim \mathcal{N}(0, \sigma^2)$. This simple operation allows the network to learn across multiple scales!
-#
+#
# In **PINA**, we have already implemented this feature as a `layer` called [`FourierFeatureEmbedding`](https://mathlab.github.io/PINA/_rst/layers/fourier_embedding.html). Below, we will build the *Multi-scale Fourier Feature Architecture*. In this architecture, multiple Fourier feature embeddings (initialized with different $\sigma$ values) are applied to the input coordinates. These embeddings are then passed through the same fully-connected neural network, and the outputs are concatenated with a final linear layer.
-#
+#
# In[6]:
@@ -237,7 +237,7 @@ def forward(self, x):
return self.final_layer(torch.cat([e1, e2], dim=-1))
-# We will train the `MultiscaleFourierNet` using the `PINN` solver.
+# We will train the `MultiscaleFourierNet` using the `PINN` solver.
# Feel free to experiment with other PINN variants as well, such as `SAPINN`, `GPINN`, `CompetitivePINN`, and others, to see how they perform on this multiscale problem.
# In[ ]:
@@ -272,17 +272,17 @@ def forward(self, x):
# It is clear that the network has learned the correct solution, with a very low error. Of course, longer training and a more expressive neural network could further improve the results!
-#
+#
# ## What's Next?
-#
+#
# Congratulations on completing the one-dimensional Poisson tutorial of **PINA** using `FourierFeatureEmbedding`! There are many potential next steps you can explore:
-#
+#
# 1. **Train the network longer or with different layer sizes**: Experiment with different configurations to improve accuracy.
-#
+#
# 2. **Understand the role of `sigma` in `FourierFeatureEmbedding`**: The original paper provides insightful details on the impact of `sigma`. It's a good next step to dive deeper into its effect.
-#
+#
# 3. **Implement the *Spatio-temporal Multi-scale Fourier Feature Architecture***: Code this architecture for a more complex, time-dependent PDE (refer to Section 3 of the original paper).
-#
+#
# 4. **...and many more!**: There are countless directions to further explore, from testing on different problems to refining the model architecture.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial14/tutorial.ipynb b/tutorials/tutorial14/tutorial.ipynb
index 291ac8e24..a12168383 100644
--- a/tutorials/tutorial14/tutorial.ipynb
+++ b/tutorials/tutorial14/tutorial.ipynb
@@ -249,7 +249,9 @@
" self.store = []\n",
"\n",
" def on_train_epoch_start(self, trainer, pl_module):\n",
- " input_ = LabelTensor(torch.tensor([[0.5]], device=pl_module.device), \"t\")\n",
+ " input_ = LabelTensor(\n",
+ " torch.tensor([[0.5]], device=pl_module.device), \"t\"\n",
+ " )\n",
"\n",
" epoch_outputs = []\n",
" for model in pl_module.models:\n",
diff --git a/tutorials/tutorial14/tutorial.py b/tutorials/tutorial14/tutorial.py
index 07297b8d1..bf1172f6a 100644
--- a/tutorials/tutorial14/tutorial.py
+++ b/tutorials/tutorial14/tutorial.py
@@ -2,11 +2,11 @@
# coding: utf-8
# # Tutorial: Learning Bifurcating PDE Solutions with Physics-Informed Deep Ensembles
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial14/tutorial.ipynb)
-#
+#
# This tutorial demonstrates how to use the Deep Ensemble Physics Informed Network (DeepEnsemblePINN) to learn PDEs exhibiting bifurcating behavior, as discussed in [*Learning and Discovering Multiple Solutions Using Physics-Informed Neural Networks with Random Initialization and Deep Ensemble*](https://arxiv.org/abs/2503.06320).
-#
+#
# Let’s begin by importing the necessary libraries.
# In[1]:
@@ -41,62 +41,62 @@
# ## Deep Ensemble
-#
+#
# Deep Ensemble methods improve model performance by leveraging the diversity of predictions generated by multiple neural networks trained on the same problem. Each network in the ensemble is trained independently—typically with different weight initializations or even slight variations in the architecture or data sampling. By combining their outputs (e.g., via averaging or majority voting), ensembles reduce overfitting, increase robustness, and improve generalization.
-#
+#
# This approach allows the ensemble to capture different perspectives of the problem, leading to more accurate and reliable predictions.
-#
+#
#
# 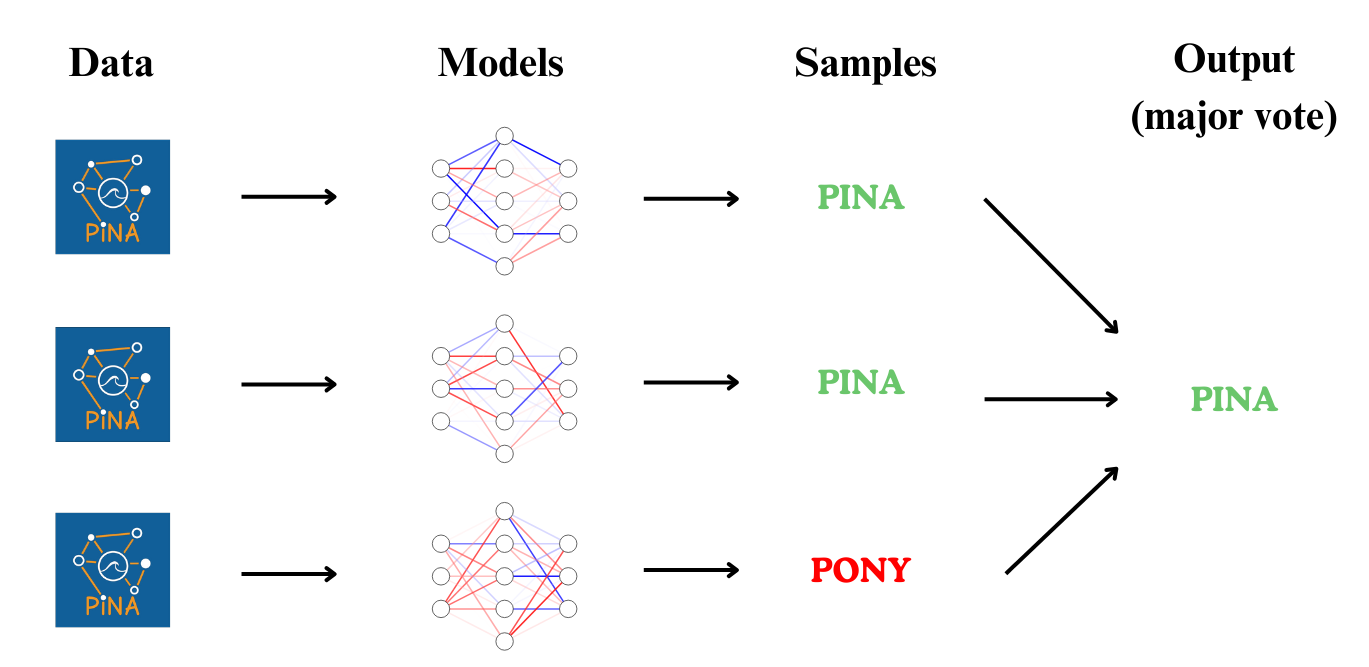 #
#
-#
+#
# The image above illustrates a Deep Ensemble setup, where multiple models attempt to predict the text from an image. While individual models may make errors (e.g., predicting "PONY" instead of "PINA"), combining their outputs—such as taking the majority vote—often leads to the correct result. This ensemble effect improves reliability by mitigating the impact of individual model biases.
-#
-#
+#
+#
# ## Deep Ensemble Physics-Informed Networks
-#
+#
# In the context of Physics-Informed Neural Networks (PINNs), Deep Ensembles help the network discover different branches or multiple solutions of a PDE that exhibits bifurcating behavior.
-#
+#
# By training a diverse set of models with different initializations, Deep Ensemble methods overcome the limitations of single-initialization models, which may converge to only one of the possible solutions. This approach is particularly useful when the solution space of the problem contains multiple valid physical states or behaviors.
-#
-#
+#
+#
# ## The Bratu Problem
-#
+#
# In this tutorial, we'll train a `DeepEnsemblePINN` solver to solve a bifurcating ODE known as the **Bratu problem**. The ODE is given by:
-#
+#
# $$
# \frac{d^2u}{dt^2} + \lambda e^u = 0, \quad t \in (0, 1)
# $$
-#
+#
# with boundary conditions:
-#
+#
# $$
# u(0) = u(1) = 0,
# $$
-#
+#
# where $\lambda > 0$ is a scalar parameter. The analytical solutions to the 1D Bratu problem can be expressed as:
-#
+#
# $$
# u(t, \alpha) = 2 \log\left(\frac{\cosh(\alpha)}{\cosh(\alpha(1 - 2t))}\right),
# $$
-#
+#
# where $\alpha$ satisfies:
-#
+#
# $$
# \cosh(\alpha) - 2\sqrt{2}\alpha = 0.
# $$
-#
+#
# When $\lambda < 3.513830719$, the equation admits two solutions $\alpha_1$ and $\alpha_2$, which correspond to two distinct solutions of the original ODE: $u_1$ and $u_2$.
-#
+#
# In this tutorial, we set $\lambda = 1$, which leads to:
-#
+#
# - $\alpha_1 \approx 0.37929$
# - $\alpha_2 \approx 2.73468$
-#
+#
# We first write the problem class, we do not write the boundary conditions as we will hard impose them.
-#
+#
# > **👉 We have a dedicated [tutorial](https://mathlab.github.io/PINA/tutorial16/tutorial.html) to teach how to build a Problem — have a look if you're interested!**
-#
+#
# > **👉 We have a dedicated [tutorial](https://mathlab.github.io/PINA/tutorial3/tutorial.html) to teach how to impose hard constraints — have a look if you're interested!**
# In[2]:
@@ -133,11 +133,11 @@ class BratuProblem(TimeDependentProblem):
# ## Defining the Deep Ensemble Models
-#
+#
# Now that the problem setup is complete, we move on to creating an **ensemble of models**. Each ensemble member will be a standard `FeedForward` neural network, wrapped inside a custom `Model` class.
-#
+#
# Each model's weights are initialized using a **normal distribution** with mean 0 and standard deviation 2. This random initialization is crucial to promote diversity across the ensemble members, allowing the models to converge to potentially different solutions of the PDE.
-#
+#
# The final ensemble is simply a **list of PyTorch models**, which we will later pass to the `DeepEnsemblePINN`
# In[3]:
@@ -177,15 +177,15 @@ def init_weights_gaussian(self):
# As you can see we get different output since the neural networks are initialized differently.
-#
+#
# ## Training with `DeepEnsemblePINN`
-#
+#
# Now that everything is ready, we can train the models using the `DeepEnsemblePINN` solver! 🎯
-#
+#
# This solver is constructed by combining multiple neural network models that all aim to solve the same PDE. Each model $\mathcal{M}_{i \in \{1, \dots, 10\}}$ in the ensemble contributes a unique perspective due to different random initializations.
-#
+#
# This diversity allows the ensemble to **capture multiple branches or bifurcating solutions** of the problem, making it especially powerful for PDEs like the Bratu problem.
-#
+#
# Once the `DeepEnsemblePINN` solver is defined with all the models, we train them using the `Trainer` class, as with any other solver in **PINA**. We also build a callback to store the value of `u(0.5)` during training iterations.
# In[ ]:
@@ -241,11 +241,11 @@ def on_train_epoch_start(self, trainer, pl_module):
# As you can see, different networks in the ensemble converge to different values pf $u(0.5)$ — this means we can actually **spot the bifurcation** in the solution space!
-#
+#
# This is a powerful demonstration of how **Deep Ensemble Physics-Informed Neural Networks** are capable of learning **multiple valid solutions** of a PDE that exhibits bifurcating behavior.
-#
+#
# We can also visualize the ensemble predictions to better observe the multiple branches:
-#
+#
# In[7]:
@@ -268,13 +268,13 @@ def on_train_epoch_start(self, trainer, pl_module):
# ## What's Next?
-#
+#
# You have completed the tutorial on deep ensemble PINNs for bifurcating PDEs, well don! There are many potential next steps you can explore:
-#
+#
# 1. **Train the network longer or with different hyperparameters**: Experiment with different configurations of the single model, you can compose an ensemble by also stacking models with different layers, activation, ... to improve accuracy.
-#
+#
# 2. **Solve more complex problems**: The original paper provides very complex problems that can be solved with PINA, we suggest you to try implement and solve them!
-#
+#
# 3. **...and many more!**: There are countless directions to further explore, for example, what does it happen when you vary the network initialization hyperparameters?
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial15/tutorial.py b/tutorials/tutorial15/tutorial.py
index b1dc51642..906f3dfea 100644
--- a/tutorials/tutorial15/tutorial.py
+++ b/tutorials/tutorial15/tutorial.py
@@ -2,15 +2,15 @@
# coding: utf-8
# # Tutorial: Chemical Properties Prediction with Graph Neural Networks
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial15/tutorial.ipynb)
-#
-# In this tutorial we will use **Graph Neural Networks** (GNNs) for chemical properties prediction. Chemical properties prediction involves estimating or determining the physical, chemical, or biological characteristics of molecules based on their structure.
-#
+#
+# In this tutorial we will use **Graph Neural Networks** (GNNs) for chemical properties prediction. Chemical properties prediction involves estimating or determining the physical, chemical, or biological characteristics of molecules based on their structure.
+#
# Molecules can naturally be represented as graphs, where atoms serve as the nodes and chemical bonds as the edges connecting them. This graph-based structure makes GNNs a great fit for predicting chemical properties.
-#
+#
# In the tutorial we will use the [QM9 dataset](https://pytorch-geometric.readthedocs.io/en/latest/generated/torch_geometric.datasets.QM9.html#torch_geometric.datasets.QM9) from Pytorch Geometric. The dataset contains small molecules, each consisting of up to 29 atoms, with every atom having a corresponding 3D position. Each atom is also represented by a five-dimensional one-hot encoded vector that indicates the atom type (H, C, N, O, F).
-#
+#
# First of all, let's start by importing useful modules!
# In[1]:
@@ -42,7 +42,7 @@
# ## Download Data and create the Problem
# We download the dataset and save the molecules as a list of `Data` objects (`input_`), where each element contains one molecule encoded in a graph structure. The corresponding target properties (`target_`) are listed below:
-#
+#
# | Target | Property | Description | Unit |
# |--------|----------------------------------|-----------------------------------------------------------------------------------|---------------------------------------------|
# | 0 | $\mu$ | Dipole moment | $D$ |
@@ -64,7 +64,7 @@
# | 16 | $A$ | Rotational constant | $GHz$ |
# | 17 | $B$ | Rotational constant | $GHz$ |
# | 18 | $C$ | Rotational constant | $GHz$ |
-#
+#
# In[2]:
@@ -92,9 +92,9 @@
# ## Build the Model
-#
+#
# To predict molecular properties, we will construct a simple Convolutional Graph Neural Network using the [`GCNConv`]() module from PyG. While this tutorial focuses on a straightforward model, more advanced architectures—such as Equivariant Networks—could potentially yield better performance. Please note that this tutorial serves only for demonstration purposes.
-#
+#
# **Importantly** notice that in the `forward` pass we pass a data object as input, and unpack inside the graph attributes. This is the only requirement in **PINA** to use graphs and solvers together.
# In[4]:
@@ -118,7 +118,7 @@ def forward(self, data):
# ## Train the Model
-#
+#
# Now that the problem is created and the model is built, we can train the model using the [`SupervisedSolver`](https://mathlab.github.io/PINA/_rst/solver/supervised.html), which is the solver for standard supervised learning task. We will optimize the Maximum Absolute Error and test on the same metric. In the [`Trainer`](https://mathlab.github.io/PINA/_rst/trainer.html) class we specify the optimization hyperparameters.
# In[ ]:
@@ -153,7 +153,7 @@ def forward(self, data):
# We observe that the model achieves an average error of approximately 0.4 MAE across all property predictions. This error is an average, but we can also inspect the error for each individual property prediction.
-#
+#
# To do this, we need access to the test dataset, which can be retrieved from the trainer's datamodule. Each datamodule contains both the dataloader and dataset objects. For the dataset, we can use the [`get_all_data()`](https://mathlab.github.io/PINA/_rst/data/dataset.html#pina.data.dataset.PinaDataset.get_all_data) method. This function returns the entire dataset as a dictionary, where the keys represent the Condition names, and the values are dictionaries containing input and target tensors.
# In[7]:
@@ -301,15 +301,15 @@ def forward(self, data):
# By looking more into details, we can see that $A$ is not predicted that well, but the small values of the quantity lead to a lower MAE than the other properties. From the plot we can see that the atomatization energies, free energy and enthalpy are the predicted properties with higher correlation with the true chemical properties.
# ## What's Next?
-#
+#
# Congratulations on completing the tutorial on chemical properties prediction with **PINA**! Now that you've got the basics, there are several exciting directions to explore:
-#
+#
# 1. **Train the network for longer or with different layer sizes**: Experiment with various configurations to see how the network's accuracy improves.
-#
+#
# 2. **Use a different network**: For example, Equivariant Graph Neural Networks (EGNNs) have shown great results on molecular tasks by leveraging group symmetries. If you're interested, check out [*E(n) Equivariant Graph Neural Networks*](https://arxiv.org/abs/2102.09844) for more details.
-#
+#
# 3. **What if the input is time-dependent?**: For example, predicting force fields in Molecular Dynamics simulations. In PINA, you can predict force fields with ease, as it's still a supervised learning task. If this interests you, have a look at [*Machine Learning Force Fields*](https://pubs.acs.org/doi/10.1021/acs.chemrev.0c01111).
-#
+#
# 4. **...and many more!**: The possibilities are vast, including exploring new architectures, working with larger datasets, and applying this framework to more complex systems.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial16/tutorial.ipynb b/tutorials/tutorial16/tutorial.ipynb
index 4408be4b8..138945177 100644
--- a/tutorials/tutorial16/tutorial.ipynb
+++ b/tutorials/tutorial16/tutorial.ipynb
@@ -412,7 +412,9 @@
"source": [
"for location in problem.discretised_domains:\n",
" coords = (\n",
- " problem.discretised_domains[location].extract(problem.spatial_variables).flatten()\n",
+ " problem.discretised_domains[location]\n",
+ " .extract(problem.spatial_variables)\n",
+ " .flatten()\n",
" )\n",
" plt.scatter(coords, torch.zeros_like(coords), s=10, label=location)\n",
"plt.legend()\n",
diff --git a/tutorials/tutorial17/tutorial.py b/tutorials/tutorial17/tutorial.py
index 0d5f71f26..ad4f5de83 100644
--- a/tutorials/tutorial17/tutorial.py
+++ b/tutorials/tutorial17/tutorial.py
@@ -2,80 +2,80 @@
# coding: utf-8
# # Tutorial: Introductory Tutorial: A Beginner’s Guide to PINA
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial17/tutorial.ipynb)
-#
+#
#
#  #
#
-#
-#
+#
+#
# Welcome to **PINA**!
-#
+#
# PINA [1] is an open-source Python library designed for **Scientific Machine Learning (SciML)** tasks, particularly involving:
-#
+#
# - **Physics-Informed Neural Networks (PINNs)**
# - **Neural Operators (NOs)**
# - **Reduced Order Models (ROMs)**
# - **Graph Neural Networks (GNNs)**
# - ...
-#
+#
# Built on **PyTorch**, **PyTorch Lightning**, and **PyTorch Geometric**, it provides a **user-friendly, intuitive interface** for formulating and solving differential problems using neural networks.
-#
+#
# This tutorial offers a **step-by-step guide** to using PINA—starting from basic to advanced techniques—enabling users to tackle a broad spectrum of differential problems with minimal code.
-#
-#
-#
+#
+#
+#
-# ## The PINA Workflow
-#
+# ## The PINA Workflow
+#
#
# 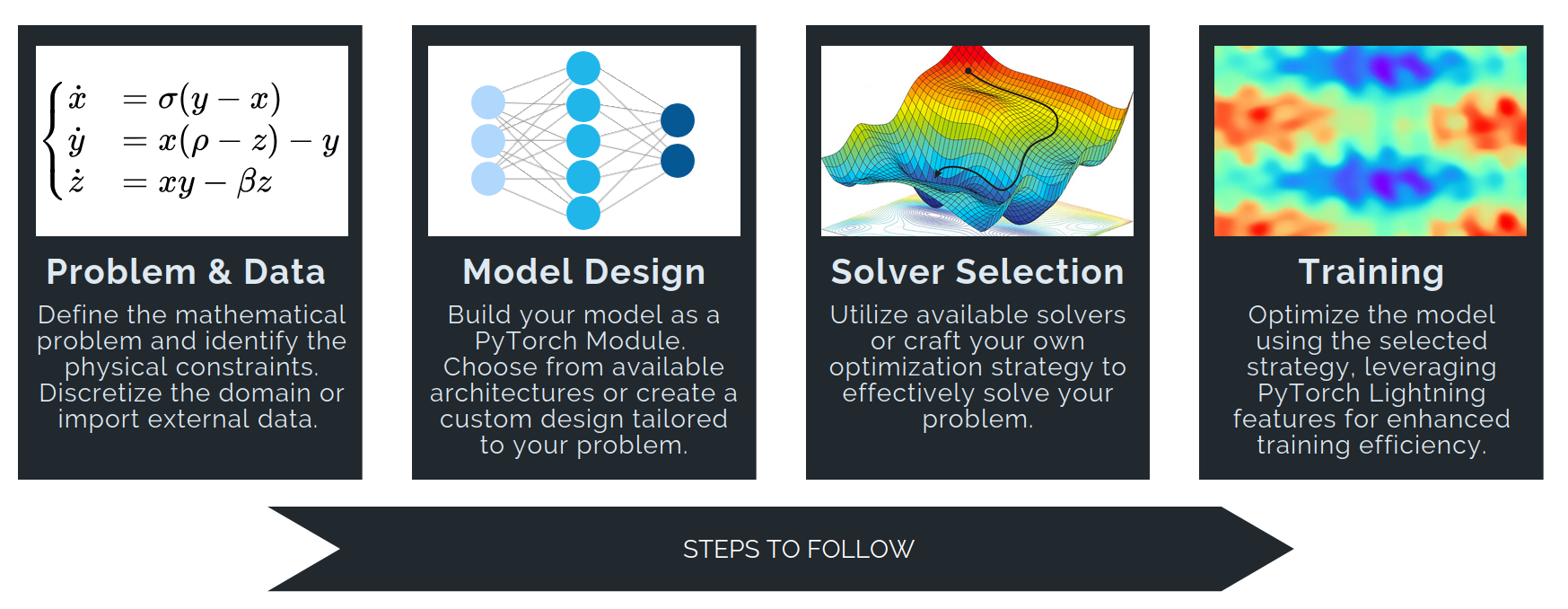 #
#
-#
+#
# Solving a differential problem in **PINA** involves four main steps:
-#
+#
# 1. ***Problem & Data***
-# Define the mathematical problem and its physical constraints using PINA’s base classes:
+# Define the mathematical problem and its physical constraints using PINA’s base classes:
# - `AbstractProblem`
# - `SpatialProblem`
-# - `InverseProblem`
+# - `InverseProblem`
# - ...
-#
+#
# Then prepare inputs by discretizing the domain or importing numerical data. PINA provides essential tools like the `Conditions` class and the `pina.domain` module to facilitate domain sampling and ensure that the input data aligns with the problem's requirements.
-#
+#
# > **👉 We have a dedicated [tutorial](https://mathlab.github.io/PINA/tutorial16/tutorial.html) to teach how to build a Problem from scratch — have a look if you're interested!**
-#
-# 2. ***Model Design***
+#
+# 2. ***Model Design***
# Build neural network models as **PyTorch modules**. For graph-structured data, use **PyTorch Geometric** to build Graph Neural Networks. You can also import models from `pina.model` module!
-#
-# 3. ***Solver Selection***
+#
+# 3. ***Solver Selection***
# Choose and configure a solver to optimize your model. Options include:
# - **Supervised solvers**: `SupervisedSolver`, `ReducedOrderModelSolver`
# - **Physics-informed solvers**: `PINN` and (many) variants
-# - **Generative solvers**: `GAROM`
+# - **Generative solvers**: `GAROM`
# Solvers can be used out-of-the-box, extended, or fully customized.
-#
-# 4. ***Training***
+#
+# 4. ***Training***
# Train your model using the `Trainer` class (built on **PyTorch Lightning**), which enables scalable and efficient training with advanced features.
-#
-#
+#
+#
# By following these steps, PINA simplifies applying deep learning to scientific computing and differential problems.
-#
-#
+#
+#
# ## A Simple Regression Problem in PINA
# We'll start with a simple regression problem [2] of approximating the following function with a Neural Net model $\mathcal{M}_{\theta}$:
-# $$y = x^3 + \epsilon, \quad \epsilon \sim \mathcal{N}(0, 9)$$
-# using only 20 samples:
-#
+# $$y = x^3 + \epsilon, \quad \epsilon \sim \mathcal{N}(0, 9)$$
+# using only 20 samples:
+#
# $$x_i \sim \mathcal{U}[-3, 3], \; \forall i \in \{1, \dots, 20\}$$
-#
+#
# Using PINA, we will:
-#
+#
# - Generate a synthetic dataset.
# - Implement a **Bayesian regressor**.
# - Use **Monte Carlo (MC) Dropout** for **Bayesian inference** and **uncertainty estimation**.
-#
+#
# This example highlights how PINA can be used for classic regression tasks with probabilistic modeling capabilities. Let's first import useful modules!
# In[1]:
@@ -101,16 +101,15 @@
from pina.problem import AbstractProblem
from pina.domain import EllipsoidDomain, Difference, CartesianDomain, Union
-
# #### ***Problem & Data***
-#
+#
# We'll start by defining a `BayesianProblem` inheriting from `AbstractProblem` to handle input/output data. This is suitable when data is available. For other cases like PDEs without data, use:
-#
+#
# - `SpatialProblem` – for spatial variables
# - `TimeDependentProblem` – for temporal variables
# - `ParametricProblem` – for parametric inputs
# - `InverseProblem` – for parameter estimation from observations
-#
+#
# but we will see this more in depth in a while!
# In[2]:
@@ -140,14 +139,14 @@ class BayesianProblem(AbstractProblem):
# We highlight two very important features of PINA
-#
-# 1. **`LabelTensor` Structure**
-# - Alongside the standard `torch.Tensor`, PINA introduces the `LabelTensor` structure, which allows **string-based indexing**.
-# - Ideal for managing and stacking tensors with different labels (e.g., `"x"`, `"t"`, `"u"`) for improved clarity and organization.
+#
+# 1. **`LabelTensor` Structure**
+# - Alongside the standard `torch.Tensor`, PINA introduces the `LabelTensor` structure, which allows **string-based indexing**.
+# - Ideal for managing and stacking tensors with different labels (e.g., `"x"`, `"t"`, `"u"`) for improved clarity and organization.
# - You can still use standard PyTorch tensors if needed.
-#
-# 2. **`Condition` Object**
-# - The `Condition` object enforces the **constraints** that the model $\mathcal{M}_{\theta}$ must satisfy, such as boundary or initial conditions.
+#
+# 2. **`Condition` Object**
+# - The `Condition` object enforces the **constraints** that the model $\mathcal{M}_{\theta}$ must satisfy, such as boundary or initial conditions.
# - It ensures that the model adheres to the specific requirements of the problem, making constraint handling more intuitive and streamlined.
# In[3]:
@@ -168,14 +167,14 @@ class BayesianProblem(AbstractProblem):
# #### ***Model Design***
-#
-# We will now solve the problem using a **simple PyTorch Neural Network** with **Dropout**, which we will implement from scratch following [2].
+#
+# We will now solve the problem using a **simple PyTorch Neural Network** with **Dropout**, which we will implement from scratch following [2].
# It's important to note that PINA provides a wide range of **state-of-the-art (SOTA)** architectures in the `pina.model` module, which you can explore further [here](https://mathlab.github.io/PINA/_rst/_code.html#models).
-#
+#
# #### ***Solver Selection***
-#
-# For this task, we will use a straightforward **supervised learning** approach by importing the `SupervisedSolver` from `pina.solvers`. The solver is responsible for defining the training strategy.
-#
+#
+# For this task, we will use a straightforward **supervised learning** approach by importing the `SupervisedSolver` from `pina.solvers`. The solver is responsible for defining the training strategy.
+#
# The `SupervisedSolver` is designed to handle typical regression tasks effectively by minimizing the following loss function:
# $$
# \mathcal{L}_{\rm{problem}} = \frac{1}{N}\sum_{i=1}^N
@@ -185,14 +184,14 @@ class BayesianProblem(AbstractProblem):
# $$
# \mathcal{L}(v) = \| v \|^2_2.
# $$
-#
+#
# #### **Training**
-#
+#
# Next, we will use the `Trainer` class to train the model. The `Trainer` class, based on **PyTorch Lightning**, offers many features that help:
# - **Improve model accuracy**
# - **Reduce training time and memory usage**
-# - **Facilitate logging and visualization**
-#
+# - **Facilitate logging and visualization**
+#
# The great work done by the PyTorch Lightning team ensures a streamlined training process.
# In[ ]:
@@ -231,15 +230,15 @@ def forward(self, x):
# #### ***Model Training Complete! Now Visualize the Solutions***
-#
+#
# The model has been trained! Since we used **Dropout** during training, the model is probabilistic (Bayesian) [3]. This means that each time we evaluate the forward pass on the input points $x_i$, the results will differ due to the stochastic nature of Dropout.
-#
+#
# To visualize the model's predictions and uncertainty, we will:
-#
+#
# 1. **Evaluate the Forward Pass**: Perform multiple forward passes to get different predictions for each input $x_i$.
# 2. **Compute the Mean**: Calculate the average prediction $\mu_\theta$ across all forward passes.
# 3. **Compute the Standard Deviation**: Calculate the variability of the predictions $\sigma_\theta$, which indicates the model's uncertainty.
-#
+#
# This allows us to understand not only the predicted values but also the confidence in those predictions.
# In[5]:
@@ -267,32 +266,32 @@ def forward(self, x):
# ## PINA for Physics-Informed Machine Learning
-#
+#
# In the previous section, we used PINA for **supervised learning**. However, one of its main strengths lies in **Physics-Informed Machine Learning (PIML)**, specifically through **Physics-Informed Neural Networks (PINNs)**.
-#
+#
# ### What Are PINNs?
-#
+#
# PINNs are deep learning models that integrate the laws of physics directly into the training process. By incorporating **differential equations** and **boundary conditions** into the loss function, PINNs allow the modeling of complex physical systems while ensuring the predictions remain consistent with scientific laws.
-#
+#
# ### Solving a 2D Poisson Problem
-#
+#
# In this section, we will solve a **2D Poisson problem** with **Dirichlet boundary conditions** on an **hourglass-shaped domain** using a simple PINN [4]. You can explore other PINN variants, e.g. [5] or [6] in PINA by visiting the [PINA solvers documentation](https://mathlab.github.io/PINA/_rst/_code.html#solvers). We aim to solve the following 2D Poisson problem:
-#
+#
# $$
# \begin{cases}
# \Delta u(x, y) = \sin{(\pi x)} \sin{(\pi y)} & \text{in } D, \\
-# u(x, y) = 0 & \text{on } \partial D
+# u(x, y) = 0 & \text{on } \partial D
# \end{cases}
# $$
-#
+#
# where $D$ is an **hourglass-shaped domain** defined as the difference between a **Cartesian domain** and two intersecting **ellipsoids**, and $\partial D$ is the boundary of the domain.
-#
+#
# ### Building Complex Domains
-#
+#
# PINA allows you to build complex geometries easily. It provides many built-in domain shapes and Boolean operators for combining them. For this problem, we will define the hourglass-shaped domain using the existing `CartesianDomain` and `EllipsoidDomain` classes, with Boolean operators like `Difference` and `Union`.
-#
+#
# > **👉 If you are interested in exploring the `domain` module in more detail, check out [this tutorial](https://mathlab.github.io/PINA/_rst/tutorials/tutorial6/tutorial.html).**
-#
+#
# In[6]:
@@ -327,7 +326,7 @@ def forward(self, x):
# #### Plotting the domain
-#
+#
# Nice! Now that we have built the domain, let's try to plot it
# In[7]:
@@ -354,11 +353,11 @@ def forward(self, x):
# #### Writing the Poisson Problem Class
-#
-# Very good! Now we will implement the problem class for the 2D Poisson problem. Unlike the previous examples, where we inherited from `AbstractProblem`, for this problem, we will inherit from the `SpatialProblem` class.
-#
+#
+# Very good! Now we will implement the problem class for the 2D Poisson problem. Unlike the previous examples, where we inherited from `AbstractProblem`, for this problem, we will inherit from the `SpatialProblem` class.
+#
# The reason for this is that the Poisson problem involves **spatial variables** as input, so we use `SpatialProblem` to handle such cases.
-#
+#
# This will allow us to define the problem with spatial dependencies and set up the neural network model accordingly.
# In[8]:
@@ -396,12 +395,12 @@ class Poisson(SpatialProblem):
# As you can see, writing the problem class for a differential equation in PINA is straightforward! The main differences are:
-#
+#
# - We inherit from **`SpatialProblem`** instead of `AbstractProblem` to account for spatial variables.
# - We use **`domain`** and **`equation`** inside the `Condition` to define the problem.
-#
+#
# The `Equation` class can be very useful for creating modular problem classes. If you're interested, check out [this tutorial](https://mathlab.github.io/PINA/_rst/tutorial12/tutorial.html) for more details. There's also a dedicated [tutorial](https://mathlab.github.io/PINA/_rst/tutorial16/tutorial.html) for building custom problems!
-#
+#
# Once the problem class is set, we need to **sample the domain** to obtain the data. PINA will automatically handle this, and if you forget to sample, an error will be raised before training begins 😉.
# In[9]:
@@ -416,13 +415,13 @@ class Poisson(SpatialProblem):
# ### Building the Model
-#
+#
# After setting the problem and sampling the domain, the next step is to **build the model** $\mathcal{M}_{\theta}$.
-#
+#
# For this, we will use the custom PINA models available [here](https://mathlab.github.io/PINA/_rst/_code.html#models). Specifically, we will use a **feed-forward neural network** by importing the `FeedForward` class.
-#
-# This neural network takes the **coordinates** (in this case `['x', 'y']`) as input and outputs the unknown field of the Poisson problem.
-#
+#
+# This neural network takes the **coordinates** (in this case `['x', 'y']`) as input and outputs the unknown field of the Poisson problem.
+#
# In this tutorial, the neural network is composed of 2 hidden layers, each with 120 neurons and tanh activation.
# In[10]:
@@ -439,30 +438,30 @@ class Poisson(SpatialProblem):
# ### Solver Selection
-#
+#
# The thir part of the PINA pipeline involves using a **Solver**.
-#
+#
# In this tutorial, we will use the **classical PINN** solver. However, many other variants are also available and we invite to try them!
-#
+#
# #### Loss Function in PINA
-#
+#
# The loss function in the **classical PINN** is defined as follows:
-#
+#
# $$\theta_{\rm{best}}=\min_{\theta}\mathcal{L}_{\rm{problem}}(\theta), \quad \mathcal{L}_{\rm{problem}}(\theta)= \frac{1}{N_{D}}\sum_{i=1}^N
# \mathcal{L}(\Delta\mathcal{M}_{\theta}(\mathbf{x}_i, \mathbf{y}_i) - \sin(\pi x_i)\sin(\pi y_i)) +
# \frac{1}{N}\sum_{i=1}^N
# \mathcal{L}(\mathcal{M}_{\theta}(\mathbf{x}_i, \mathbf{y}_i))$$
-#
+#
# This loss consists of:
# 1. The **differential equation residual**: Ensures the model satisfies the Poisson equation.
# 2. The **boundary condition**: Ensures the model satisfies the Dirichlet boundary condition.
-#
+#
# ### Training
-#
+#
# For the last part of the pipeline we need a `Trainer`. We will train the model for **1000 epochs** using the default optimizer parameters. These parameters can be adjusted as needed. For more details, check the solvers documentation [here](https://mathlab.github.io/PINA/_rst/_code.html#solvers).
-#
+#
# To track metrics during training, we use the **`MetricTracker`** class.
-#
+#
# > **👉 Want to know more about `Trainer` and how to boost PINA performance, check out [this tutorial](https://mathlab.github.io/PINA/_rst/tutorials/tutorial11/tutorial.html).**
# In[ ]:
@@ -521,28 +520,28 @@ class Poisson(SpatialProblem):
# ## What's Next?
-#
+#
# Congratulations on completing the introductory tutorial of **PINA**! Now that you have a solid foundation, here are a few directions you can explore:
-#
+#
# 1. **Explore Advanced Solvers**: Dive into more advanced solvers like **SAPINN** or **RBAPINN** and experiment with different variations of Physics-Informed Neural Networks.
# 2. **Apply PINA to New Problems**: Try solving other types of differential equations or explore inverse problems and parametric problems using the PINA framework.
# 3. **Optimize Model Performance**: Use the `Trainer` class to enhance model performance by exploring features like dynamic learning rates, early stopping, and model checkpoints.
-#
+#
# 4. **...and many more!** — There are countless directions to further explore, from testing on different problems to refining the model architecture!
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
-#
-#
+#
+#
# ### References
-#
+#
# [1] *Coscia, Dario, et al. "Physics-informed neural networks for advanced modeling." Journal of Open Source Software, 2023.*
-#
+#
# [2] *Hernández-Lobato, José Miguel, and Ryan Adams. "Probabilistic backpropagation for scalable learning of bayesian neural networks." International conference on machine learning, 2015.*
-#
+#
# [3] *Gal, Yarin, and Zoubin Ghahramani. "Dropout as a bayesian approximation: Representing model uncertainty in deep learning." International conference on machine learning, 2016.*
-#
+#
# [4] *Raissi, Maziar, Paris Perdikaris, and George E. Karniadakis. "Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations." Journal of Computational Physics, 2019.*
-#
+#
# [5] *McClenny, Levi D., and Ulisses M. Braga-Neto. "Self-adaptive physics-informed neural networks." Journal of Computational Physics, 2023.*
-#
+#
# [6] *Anagnostopoulos, Sokratis J., et al. "Residual-based attention in physics-informed neural networks." Computer Methods in Applied Mechanics and Engineering, 2024.*
diff --git a/tutorials/tutorial18/tutorial.py b/tutorials/tutorial18/tutorial.py
index fc3647d65..25e686653 100644
--- a/tutorials/tutorial18/tutorial.py
+++ b/tutorials/tutorial18/tutorial.py
@@ -2,29 +2,29 @@
# coding: utf-8
# # Tutorial: Introduction to Solver classes
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial18/tutorial.ipynb)
-#
+#
# In this tutorial, we will explore the Solver classes in PINA, that are the core components for optimizing models. Solvers are designed to manage and execute the optimization process, providing the flexibility to work with various types of neural networks and loss functions. We will show how to use this class to select and implement different solvers, such as Supervised Learning, Physics-Informed Neural Networks (PINNs), and Generative Learning solvers. By the end of this tutorial, you'll be equipped to easily choose and customize solvers for your own tasks, streamlining the model training process.
-#
+#
# ## Introduction to Solvers
-#
+#
# [`Solvers`](https://mathlab.github.io/PINA/_rst/_code.html#solvers) are versatile objects in PINA designed to manage the training and optimization of machine learning models. They handle key components of the learning process, including:
-#
-# - Loss function minimization
+#
+# - Loss function minimization
# - Model optimization (optimizer, schedulers)
# - Validation and testing workflows
-#
+#
# PINA solvers are built on top of the [PyTorch Lightning `LightningModule`](https://lightning.ai/docs/pytorch/stable/common/lightning_module.html), which provides a structured and scalable training framework. This allows solvers to leverage advanced features such as distributed training, early stopping, and logging — all with minimal setup.
-#
+#
# ## Solvers Hierarchy: Single and MultiSolver
-#
+#
# PINA provides two main abstract interfaces for solvers, depending on whether the training involves a single model or multiple models. These interfaces define the base functionality that all specific solver implementations inherit from.
-#
+#
# ### 1. [`SingleSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/solver_interface.html)
-#
+#
# This is the abstract base class for solvers that train **a single model**, such as in standard supervised learning or physics-informed training. All specific solvers (e.g., `SupervisedSolver`, `PINN`) inherit from this interface.
-#
+#
# **Arguments:**
# - `problem` – The problem to be solved.
# - `model` – The neural network model.
@@ -32,13 +32,13 @@
# - `scheduler` – Defaults to `torch.optim.lr_scheduler.ConstantLR`.
# - `weighting` – Optional loss weighting schema., see [here](https://mathlab.github.io/PINA/_rst/_code.html#losses-and-weightings). We weight already for you!
# - `use_lt` – Whether to use LabelTensors as input.
-#
+#
# ---
-#
+#
# ### 2. [`MultiSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/multi_solver_interface.html)
-#
+#
# This is the abstract base class for solvers involving **multiple models**, such as in GAN architectures or ensemble training strategies. All multi-model solvers (e.g., `DeepEnsemblePINN`, `GAROM`) inherit from this interface.
-#
+#
# **Arguments:**
# - `problem` – The problem to be solved.
# - `models` – The model or models used for training.
@@ -46,19 +46,19 @@
# - `schedulers` – Defaults to `torch.optim.lr_scheduler.ConstantLR`.
# - `weightings` – Optional loss weighting schema, see [here](https://mathlab.github.io/PINA/_rst/_code.html#losses-and-weightings). We weight already for you!
# - `use_lt` – Whether to use LabelTensors as input.
-#
+#
# ---
-#
-# These base classes define the structure and behavior of solvers in PINA, allowing you to create customized training strategies while leveraging PyTorch Lightning's features under the hood.
-#
+#
+# These base classes define the structure and behavior of solvers in PINA, allowing you to create customized training strategies while leveraging PyTorch Lightning's features under the hood.
+#
# These classes are used to define the backbone, i.e. setting the problem, the model(s), the optimizer(s) and scheduler(s), but miss a key component the `optimization_cycle` method.
-#
-#
+#
+#
# ## Optimization Cycle
# The `optimization_cycle` method is the core function responsible for computing losses for **all conditions** in a given training batch. Each condition (e.g. initial condition, boundary condition, PDE residual) contributes its own loss, which is tracked and returned in a dictionary. This method should return a dictionary mapping **condition names** to their respective **scalar loss values**.
-#
+#
# For supervised learning tasks, where each condition consists of an input-target pair, for example, the `optimization_cycle` may look like this:
-#
+#
# ```python
# def optimization_cycle(self, batch):
# """
@@ -73,12 +73,12 @@
# return condition_loss
# ```
# In PINA, a **batch** is structured as a list of tuples, where each tuple corresponds to a specific training condition. Each tuple contains:
-#
+#
# - The **name of the condition**
# - A **dictionary of data** associated with that condition
-#
+#
# for example:
-#
+#
# ```python
# batch = [
# ("condition1", {"input": ..., "target": ...}),
@@ -86,52 +86,52 @@
# ("condition3", {"input": ..., "target": ...}),
# ]
# ```
-#
+#
# Fortunately, you don't need to implement the `optimization_cycle` yourself in most cases — PINA already provides default implementations tailored to common solver types. These implementations are available through the solver interfaces and cover various training strategies.
-#
-# 1. [`PINNInterface`](https://mathlab.github.io/PINA/_rst/solver/physics_informed_solver/pinn_interface.html)
-# Implements the optimization cycle for **physics-based solvers** (e.g., PDE residual minimization) as well as other useful methods to compute PDE residuals.
+#
+# 1. [`PINNInterface`](https://mathlab.github.io/PINA/_rst/solver/physics_informed_solver/pinn_interface.html)
+# Implements the optimization cycle for **physics-based solvers** (e.g., PDE residual minimization) as well as other useful methods to compute PDE residuals.
# ➤ [View method](https://mathlab.github.io/PINA/_rst/solver/physics_informed_solver/pinn_interface.html#pina.solver.physics_informed_solver.pinn_interface.PINNInterface.optimization_cycle)
-#
-# 2. [`SupervisedSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/supervised_solver/supervised_solver_interface.html)
-# Defines the optimization cycle for **supervised learning tasks**, including traditional regression and classification.
+#
+# 2. [`SupervisedSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/supervised_solver/supervised_solver_interface.html)
+# Defines the optimization cycle for **supervised learning tasks**, including traditional regression and classification.
# ➤ [View method](https://mathlab.github.io/PINA/_rst/solver/supervised_solver/supervised_solver_interface.html#pina.solver.supervised_solver.supervised_solver_interface.SupervisedSolverInterface.optimization_cycle)
-#
-# 3. [`DeepEnsembleSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/ensemble_solver/ensemble_solver_interface.html)
-# Provides the optimization logic for **deep ensemble methods**, commonly used for uncertainty quantification or robustness.
+#
+# 3. [`DeepEnsembleSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/ensemble_solver/ensemble_solver_interface.html)
+# Provides the optimization logic for **deep ensemble methods**, commonly used for uncertainty quantification or robustness.
# ➤ [View method](https://mathlab.github.io/PINA/_rst/solver/ensemble_solver/ensemble_solver_interface.html#pina.solver.ensemble_solver.ensemble_solver_interface.DeepEnsembleSolverInterface.optimization_cycle)
-#
+#
# These ready-to-use implementations ensure that your solvers are properly structured and compatible with PINA’s training workflow. You can also inherit and override them to fit more specialized needs. They only require, the following arguments:
# **Arguments:**
# - `problem` – The problem to be solved.
# - `loss` - The loss to be minimized
# - `weightings` – Optional loss weighting schema.
# - `use_lt` – Whether to use LabelTensors as input.
-#
+#
# ## Structure a Solver with Multiple Inheritance:
-#
+#
# Thanks to PINA’s modular design, creating a custom solver is straightforward using **multiple inheritance**. You can combine different interfaces to define both the **optimization logic** and the **model structure**.
-#
+#
# - **`PINN` Solver**
-# - Inherits from:
-# - [`PINNInterface`](https://mathlab.github.io/PINA/_rst/solver/physics_informed_solver/pinn_interface.html) → physics-based optimization loop
+# - Inherits from:
+# - [`PINNInterface`](https://mathlab.github.io/PINA/_rst/solver/physics_informed_solver/pinn_interface.html) → physics-based optimization loop
# - [`SingleSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/solver_interface.html) → training a single model
-#
+#
# - **`SupervisedSolver`**
-# - Inherits from:
-# - [`SupervisedSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/supervised_solver/supervised_solver_interface.html) → data-driven optimization loop
+# - Inherits from:
+# - [`SupervisedSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/supervised_solver/supervised_solver_interface.html) → data-driven optimization loop
# - [`SingleSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/solver_interface.html) → training a single model
-#
+#
# - **`GAROM`** (a variant of GAN)
-# - Inherits from:
-# - [`SupervisedSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/supervised_solver/supervised_solver_interface.html) → data-driven optimization loop
+# - Inherits from:
+# - [`SupervisedSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/supervised_solver/supervised_solver_interface.html) → data-driven optimization loop
# - [`MultiSolverInterface`](https://mathlab.github.io/PINA/_rst/solver/multi_solver_interface.html) → training multiple models (e.g., generator and discriminator)
-#
+#
# This structure promotes **code reuse** and **extensibility**, allowing you to quickly prototype new solver strategies by reusing core training and optimization logic.
-#
+#
# ## Let's try to build some solvers!
-#
-# We will now start building a simple supervised solver in PINA. Let's first import useful modules!
+#
+# We will now start building a simple supervised solver in PINA. Let's first import useful modules!
# In[1]:
@@ -157,9 +157,8 @@
from pina.model import FeedForward
from pina.problem.zoo import SupervisedProblem
-
# Since we are using only one model for this task, we will inherit from two base classes:
-#
+#
# - `SingleSolverInterface`: This ensures we are working with a single model.
# - `SupervisedSolverInterface`: This allows us to use supervised learning strategies for training the model.
@@ -189,9 +188,9 @@ def __init__(
# By default, Python follows a specific method resolution order (MRO) when a class inherits from multiple parent classes. This means that the initialization (`__init__`) method is called based on the order of inheritance.
-#
-# Since we inherit from `SupervisedSolverInterface` first, Python will call the `__init__` method from `SupervisedSolverInterface` (initialize `problem`, `loss`, `weighting` and `use_lt`) before calling the `__init__` method from `SingleSolverInterface` (initialize `model`, `optimizer`, `scheduler`). This allows us to customize the initialization process for our custom solver.
-#
+#
+# Since we inherit from `SupervisedSolverInterface` first, Python will call the `__init__` method from `SupervisedSolverInterface` (initialize `problem`, `loss`, `weighting` and `use_lt`) before calling the `__init__` method from `SingleSolverInterface` (initialize `model`, `optimizer`, `scheduler`). This allows us to customize the initialization process for our custom solver.
+#
# We will learn a very simple problem, try to learn $y=\sin(x)$.
# In[3]:
@@ -207,23 +206,23 @@ def __init__(
# If we now try to initialize the solver `MyFirstSolver` we will get the following error:
-#
+#
# ```python
# ---------------------------------------------------------------------------
# TypeError Traceback (most recent call last)
# Cell In[41], line 1
# ----> 1 MyFirstSolver(problem, model)
-#
+#
# TypeError: Can't instantiate abstract class MyFirstSolver with abstract method loss_data
# ```
-#
+#
# ### Data and Physics Loss
# The error above is because in PINA, all solvers must specify how to compute the loss during training. There are two main types of losses that can be computed, depending on the nature of the problem:
-#
+#
# 1. **`loss_data`**: Computes the **data loss** between the model's output and the true solution. This is typically used in **supervised learning** setups, where we have ground truth data to compare the model's predictions. It expects some `input` (tensor, graph, ...) and a `target` (tensor, graph, ...)
-#
+#
# 2. **`loss_phys`**: Computes the **physics loss** for **physics-informed solvers** (PINNs). This loss is based on the residuals of the governing equations that model physical systems, enforcing the equations during training. It expects some `samples` (`LabelTensor`) and an `equation` (`Equation`)
-#
+#
# Therefore our implementation becomes:
# In[ ]:
@@ -268,33 +267,33 @@ def loss_data(self, input, target):
# ## A Summary on Solvers
-#
+#
# Solvers in PINA play a critical role in training and optimizing machine learning models, especially when working with complex problems like physics-informed neural networks (PINNs) or standard supervised learning. Here’s a quick recap of the key concepts we've covered:
-#
+#
# 1. **Solver Interfaces**:
# - **`SingleSolverInterface`**: For solvers using one model (e.g., a standard supervised solver or a single physics-informed model).
# - **`MultiSolverInterface`**: For solvers using multiple models (e.g., Generative Adversarial Networks (GANs)).
-#
+#
# 2. **Loss Functions**:
# - **`loss_data`**: Computes the loss for supervised solvers, typically comparing the model's predictions to the true targets.
# - **`loss_phys`**: Computes the physics loss for PINNs, typically using the residuals of a physical equation to enforce consistency with the physics of the system.
-#
+#
# 3. **Custom Solver Implementation**:
# - You can create custom solvers by inheriting from base classes such as `SingleSolverInterface`. The **`optimization_cycle`** method must be implemented to define how to compute the loss for each batch.
# - `SupervisedSolverInterface`, `PINNInterface` already implement the `optimization_cycle` for you!
-#
-#
+#
+#
# By understanding and implementing solvers in PINA, you can build flexible, scalable models that can be optimized both with traditional supervised learning techniques and more specialized, physics-based methods.
# ## What's Next?
-#
+#
# Congratulations on completing the tutorial on solver classes! Now that you have a solid foundation, here are a few directions you can explore:
-#
-#
+#
+#
# 1. **Physics Solvers**: Try to implement your own physics-based solver. Can you do it? This will involve creating a custom loss function that enforces the physics of a given problem insied `loss_phys`.
-#
+#
# 2. **Multi-Model Solvers**: Take it to the next level by exploring multi-model solvers, such as GANs or ensemble-based solvers. You could implement and train models that combine the strengths of multiple neural networks.
-#
+#
# 3. **...and many more!**: There are countless directions to further explore, try to look at our `solver` for example!
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial19/tutorial.py b/tutorials/tutorial19/tutorial.py
index c5af084b6..aa340cc92 100644
--- a/tutorials/tutorial19/tutorial.py
+++ b/tutorials/tutorial19/tutorial.py
@@ -32,7 +32,6 @@
from pina import LabelTensor, Graph
-
# ## PyTorch Tensors
#
# A **tensor** is a multi-dimensional matrix used for storing and manipulating data in PyTorch. It's the basic building block for all computations in PyTorch, including deep learning models.
diff --git a/tutorials/tutorial2/tutorial.py b/tutorials/tutorial2/tutorial.py
index 0047c81f5..f69707517 100644
--- a/tutorials/tutorial2/tutorial.py
+++ b/tutorials/tutorial2/tutorial.py
@@ -2,11 +2,11 @@
# coding: utf-8
# # Tutorial: Enhancing PINNs with Extra Features to solve the Poisson Problem
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial2/tutorial.ipynb)
-#
+#
# This tutorial presents how to solve with Physics-Informed Neural Networks (PINNs) a 2D Poisson problem with Dirichlet boundary conditions. We will train with standard PINN's training, and with extrafeatures. For more insights on extrafeature learning please read [*An extended physics informed neural network for preliminary analysis of parametric optimal control problems*](https://www.sciencedirect.com/science/article/abs/pii/S0898122123002018).
-#
+#
# First of all, some useful imports.
# In[1]:
@@ -44,10 +44,10 @@
# \end{cases}
# \end{equation}
# where $D$ is a square domain $[0,1]^2$, and $\Gamma_i$, with $i=1,...,4$, are the boundaries of the square.
-#
+#
# The Poisson problem is written in **PINA** code as a class. The equations are written as *conditions* that should be satisfied in the corresponding domains. The *solution*
# is the exact solution which will be compared with the predicted one. If interested in how to write problems see [this tutorial](https://mathlab.github.io/PINA/_rst/tutorials/tutorial16/tutorial.html).
-#
+#
# We will directly import the problem from `pina.problem.zoo`, which contains a vast list of PINN problems and more.
# In[2]:
@@ -72,7 +72,7 @@
# ## Solving the problem with standard PINNs
# After the problem, the feed-forward neural network is defined, through the class `FeedForward`. This neural network takes as input the coordinates (in this case $x$ and $y$) and provides the unkwown field of the Poisson problem. The residual of the equations are evaluated at several sampling points and the loss minimized by the neural network is the sum of the residuals.
-#
+#
# In this tutorial, the neural network is composed by two hidden layers of 10 neurons each, and it is trained for 1000 epochs with a learning rate of 0.006 and $l_2$ weight regularization set to $10^{-8}$. These parameters can be modified as desired. We set the `train_size` to 0.8 and `test_size` to 0.2, this mean that the discretised points will be divided in a 80%-20% fashion, where 80% will be used for training and the remaining 20% for testing.
# In[ ]:
@@ -108,7 +108,7 @@
# Now we plot the results using `matplotlib`.
-# The solution predicted by the neural network is plotted on the left, the exact one is in the center and on the right the error between the exact and the predicted solutions is showed.
+# The solution predicted by the neural network is plotted on the left, the exact one is in the center and on the right the error between the exact and the predicted solutions is showed.
# In[4]:
@@ -153,17 +153,17 @@ def plot_solution(solver):
# ## Solving the problem with extra-features PINNs
# Now, the same problem is solved in a different way.
-# A new neural network is now defined, with an additional input variable, named extra-feature, which coincides with the forcing term in the Laplace equation.
+# A new neural network is now defined, with an additional input variable, named extra-feature, which coincides with the forcing term in the Laplace equation.
# The set of input variables to the neural network is:
-#
+#
# \begin{equation}
# [x, y, k(x, y)], \text{ with } k(x, y)= 2\pi^2\sin{(\pi x)}\sin{(\pi y)},
# \end{equation}
-#
+#
# where $x$ and $y$ are the spatial coordinates and $k(x, y)$ is the added feature which is equal to the forcing term.
-#
+#
# This feature is initialized in the class `SinSin`, which is a simple `torch.nn.Module`. After declaring such feature, we can just adjust the `FeedForward` class by creating a subclass `FeedForwardWithExtraFeatures` with an adjusted forward method and the additional attribute `extra_features`.
-#
+#
# Finally, we perform the same training as before: the problem is `Poisson`, the network is composed by the same number of neurons and optimizer parameters are equal to previous test, the only change is the new extra feature.
# In[ ]:
@@ -232,14 +232,14 @@ def forward(self, x):
# ## Solving the problem with learnable extra-features PINNs
# We can still do better!
-#
+#
# Another way to exploit the extra features is the addition of learnable parameter inside them.
# In this way, the added parameters are learned during the training phase of the neural network. In this case, we use:
-#
+#
# \begin{equation}
# k(x, \mathbf{y}) = \beta \sin{(\alpha x)} \sin{(\alpha y)},
# \end{equation}
-#
+#
# where $\alpha$ and $\beta$ are the abovementioned parameters.
# Their implementation is quite trivial: by using the class `torch.nn.Parameter` we cam define all the learnable parameters we need, and they are managed by `autograd` module!
@@ -344,15 +344,15 @@ def forward(self, x):
# ## What's Next?
-#
+#
# Congratulations on completing the two-dimensional Poisson tutorial of **PINA**! Now that you've learned the basics, there are multiple directions you can explore:
-#
+#
# 1. **Train the Network for Longer**: Continue training the network for a longer duration or experiment with different layer sizes to assess the final accuracy.
-#
+#
# 2. **Propose New Types of Extrafeatures**: Experiment with new extrafeatures and investigate how they affect the learning process.
-#
+#
# 3. **Leverage Extrafeature Training for Complex Problems**: Apply extrafeature training techniques to more complex problems to improve model performance.
-#
+#
# 4. **... and many more!.**: There are endless possibilities! Continue exploring and experimenting with new ideas.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial20/tutorial.py b/tutorials/tutorial20/tutorial.py
index d74079065..00541041e 100644
--- a/tutorials/tutorial20/tutorial.py
+++ b/tutorials/tutorial20/tutorial.py
@@ -2,15 +2,15 @@
# coding: utf-8
# # Tutorial: Introductory Tutorial: Supervised Learning with PINA
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial20/tutorial.ipynb)
-#
-#
+#
+#
# > ##### ⚠️ ***Before starting:***
# > We assume you are already familiar with the concepts covered in the [Getting started with PINA](https://mathlab.github.io/PINA/_tutorial.html#getting-started-with-pina) tutorials. If not, we strongly recommend reviewing them before exploring this advanced topic.
-#
+#
# In this tutorial, we will demonstrate a typical use case of **PINA** for Supervised Learning training. We will cover the basics of training a Supervised Solver with PINA, if you want to go further into PINNs look at our dedicated [tutorials](https://mathlab.github.io/PINA/_tutorial.html#supervised-learning) on the topic.
-#
+#
# Let's start by importing the useful modules:
# In[1]:
@@ -40,24 +40,23 @@
from pina.adaptive_function import AdaptiveSIREN
from pina.problem.zoo import SupervisedProblem
-
# ## Building a Neural Implicit Field for a Sphere
-#
+#
# In this tutorial, we will construct a **Neural Implicit Field** to learn the **Signed Distance Function (SDF)** of a sphere. The problem is relatively simple: we aim to learn a function $d_\theta$, parameterized by a neural network, that captures the signed distance to the surface of a sphere.
-#
+#
# The function $d_\theta(\mathbf{x})$$ should satisfy the following properties:
-#
-# - $d_\theta(\mathbf{x}) = 0$ on the surface of the sphere
-# - $d_\theta(\mathbf{x}) > 0$ outside the sphere
-# - $d_\theta(\mathbf{x}) < 0$ inside the sphere
-#
+#
+# - $d_\theta(\mathbf{x}) = 0$ on the surface of the sphere
+# - $d_\theta(\mathbf{x}) > 0$ outside the sphere
+# - $d_\theta(\mathbf{x}) < 0$ inside the sphere
+#
# This setup allows us to implicitly represent the geometry of the sphere through the learned function.
-#
+#
# ### Mathematical Description
-#
+#
# We define the signed distance function (SDF) for a sphere centered at the origin with radius $r$ as:
# $d(\mathbf{x}) = \|\mathbf{x}\| - r$, where $\mathbf{x} \in \mathbb{R}^3$ is a point in 3D space.
-#
+#
# Our goal is to approximate this function using a neural network: $d_\theta(\mathbf{x}) \approx d(\mathbf{x})$ with a Neural Network. Let's start by generating the data for the problem by:
# 1. Sample random 3D points within a bounding cube (e.g., $[-1.5, 1.5]^3$).
# 2. Compute their ground truth signed distances from a sphere of radius $r$ centered at the origin.
@@ -84,7 +83,7 @@ def generate_sdf_data(num_points=1000000, radius=1.0, cube_bound=1.5):
# ### Visualizing the Data
-#
+#
# To better understand the problem and the nature of the solutions, we can visualize the generated data:
# In[3]:
@@ -113,9 +112,9 @@ def generate_sdf_data(num_points=1000000, radius=1.0, cube_bound=1.5):
# ## Creating the Problem
-#
+#
# The problem we will define is a basic `SupervisedProblem`, where the inputs are the coordinates and the outputs are the corresponding Signed Distance Function (SDF) values.
-#
+#
# > **👉 We have a dedicated [tutorial](https://mathlab.github.io/PINA/tutorial16/tutorial.html) to teach how to build a Problem from scratch — have a look if you're interested!**
# In[4]:
@@ -125,16 +124,16 @@ def generate_sdf_data(num_points=1000000, radius=1.0, cube_bound=1.5):
# ## Solving the Problem with Supervised Solver
-#
+#
# We will use the `SupervisedSolver` to solve the task. A Supervised Solver in PINA aims to find a mapping between an input \( x \) and an output \( y \).
# Given a PINA `model` $\mathcal{M}$, the following loss function is minimized during training:
-#
+#
# $$
# \mathcal{L}_{\rm{supervised}} = \frac{1}{N}\sum_{i=1}^N \mathcal{l}(y_i, \mathcal{M}(x_i)),
# $$
-#
+#
# where $l$ is a specific loss function, typically the MSE (Mean Squared Error).
-#
+#
# ### Specify the Loss Function
# By default, the loss function applies a forward pass of the `model` on the input and compares it to the target using the `loss` attribute of `SupervisedSolver`. The [`loss_data`](https://mathlab.github.io/PINA/_rst/solver/supervised.html#pina.solver.supervised.SupervisedSolver.loss_data) function computes the loss for supervised solvers, and it can be overridden by the user to match specific needs (e.g., performing pre-process operations on the input, post-process operations on the output, etc.).
@@ -162,9 +161,9 @@ def generate_sdf_data(num_points=1000000, radius=1.0, cube_bound=1.5):
# ## Visualizing the Predictions
-#
+#
# As we can see, we have achieved a very low MSE, even after training for only one epoch. Now, we will visualize the results in the same way as we did previously:
-#
+#
# We will plot the predicted Signed Distance Function (SDF) values alongside the true SDF values to evaluate the model's performance.
# In[6]:
@@ -222,9 +221,9 @@ def generate_sdf_data(num_points=1000000, radius=1.0, cube_bound=1.5):
# Nice! We can see that the network is correctly learning the signed distance function! Let's now visualize the rendering of the sphere surface learned by the network.
-#
+#
# ### Visualizing the Sphere Surface
-#
+#
# To visualize the surface, we will extract the level set where the SDF equals zero and plot the resulting sphere. This will show how well the network has learned the geometry of the object.
# In[7]:
@@ -262,14 +261,14 @@ def generate_sdf_data(num_points=1000000, radius=1.0, cube_bound=1.5):
# ## What's Next?
-#
+#
# Congratulations on completing the introductiory tutorial on supervised solver! Now that you have a solid foundation, here are a few directions you can explore:
-#
-#
+#
+#
# 1. **Experiment with Training Duration & Network Architecture**: Try different training durations and tweak the network architecture to optimize performance.
-#
+#
# 2. **Explore Other Models in `pina.model`**: Check out other models available in `pina.model` or design your own custom PyTorch module to suit your needs.
-#
+#
# 3. **... and many more!**: The possibilities are vast! Continue experimenting with advanced configurations, solvers, and other features in PINA.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial21/tutorial.py b/tutorials/tutorial21/tutorial.py
index ac8f90446..249a30cf3 100644
--- a/tutorials/tutorial21/tutorial.py
+++ b/tutorials/tutorial21/tutorial.py
@@ -2,15 +2,15 @@
# coding: utf-8
# # Tutorial: Introductory Tutorial: Neural Operator Learning with PINA
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial21/tutorial.ipynb)
-#
-#
+#
+#
# > ##### ⚠️ ***Before starting:***
# > We assume you are already familiar with the concepts covered in the [Getting started with PINA](https://mathlab.github.io/PINA/_tutorial.html#getting-started-with-pina) tutorials. If not, we strongly recommend reviewing them before exploring this advanced topic.
-#
+#
# In this tutorial, we will demonstrate a typical use case of **PINA** for Neural Operator learning. We will cover the basics of training a Neural Operator with PINA, if you want to go further into the topic look at our dedicated [tutorials](https://mathlab.github.io/PINA/_tutorial.html#neural-operator-learning) on the topic.
-#
+#
# Let's start by importing the useful modules:
# In[ ]:
@@ -38,57 +38,56 @@
from pina.model.block import FourierBlock1D
from pina.problem.zoo import SupervisedProblem
-
# ## Learning Differential Operators via Neural Operator
-#
+#
# In this tutorial, we explore how **Neural Operators** can be used to learn and approximate **differential operators**, which are fundamental in modeling physical and engineering systems governed by differential equations.
-#
+#
# ### What Are Neural Operators?
-#
+#
# **Neural Operators (NOs)** are a class of machine learning models designed to learn mappings *between function spaces*, unlike traditional neural networks which learn mappings between finite-dimensional vectors. In the context of differential equations, this means a Neural Operator can learn the **solution operator**:
# $$
# \mathcal{G}(a) = u,
# $$
# where $a$ is an input function (e.g., a PDE coefficient) and $u$ is the solution function.
-#
+#
# ### Why Are Neural Operators Useful?
-#
+#
# - **Mesh-free learning**: Neural Operators work directly with functions, allowing them to generalize across different spatial resolutions or grids.
# - **Fast inference**: Once trained, they can predict the solution of a PDE for new input data almost instantaneously.
# - **Physics-aware extensions**: Some variants can incorporate physical laws and constraints into the training process, improving accuracy and generalization.
-#
+#
# ## Learning the 1D Advection Equation with a Neural Operator
-#
+#
# To make things concrete, we'll a Neural Operator to learn the 1D advection equation. We generate synthetic data based on the analytical solution:
-#
+#
# $$
# \frac{\partial u}{\partial t} + c \frac{\partial u}{\partial x} = 0
# $$
-#
+#
# For a given initial condition $u(x, 0)$, the exact solution at time $t$ is:
-#
+#
# $$
# u(x, t) = u(x - ct)
# $$
-#
+#
# We use this property to generate training data without solving the PDE numerically.
-#
+#
# ### Problem Setup
-#
+#
# 1. **Define the spatial domain**: We work on a 1D grid $x \in [0, 1]$ with periodic boundary conditions.
-#
+#
# 2. **Generate initial conditions**: Each initial condition $u(x, 0)$ is created as a sum of sine waves with random amplitudes and phases:
# $$
# u(x, 0) = \sum_{k=1}^K A_k \sin(2\pi k x + \phi_k)
# $$
# where $A_k \in [0, 0.5]$ and $\phi_k \in [0, 2\pi]$ are sampled randomly for each sample.
-#
-# 3. **Compute the solution at time $t$**:
+#
+# 3. **Compute the solution at time $t$**:
# Using the analytical solution, we shift each initial condition by $t=0.5$ ($c=1$), applying periodic wrap-around:
# $$
# u(x, t=0.5) = u(x - 0.5)
# $$
-#
+#
# 4. **Create input-output pairs**: The input to the model is the function $u(x, 0)$, and the target output is $u(x, 0.5)$. These pairs can be used to train a Neural Operator to learn the underlying differential operator.
# In[18]:
@@ -123,59 +122,59 @@ def generate_data(n_samples, x, c=1, t=0.5):
# ## Solving the Neural Operator Problem
-#
+#
# At their core, **Neural Operators** transform an input function $a$ into an output function $u$. The general structure of a Neural Operator consists of three key components:
-#
+#
#
#  #
#
-#
+#
# 1. **Encoder**: The encoder maps the input into a specific embedding space.
-#
-# 2. **Processor**: The processor consists of multiple layers performing **function convolutions**, which is the core computational unit in a Neural Operator.
+#
+# 2. **Processor**: The processor consists of multiple layers performing **function convolutions**, which is the core computational unit in a Neural Operator.
# 3. **Decoder**: The decoder maps the processor's output back into the desired output space.
-#
+#
# By varying the design and implementation of these three components — encoder, processor, and decoder — different Neural Operators are created, each tailored for specific applications or types of data.
-#
+#
# ### Types of Neural Operators
-#
+#
# Different variants of Neural Operators are designed to solve specific tasks. Some prominent examples include:
-#
-# - **Fourier Neural Operator (FNO)**:
-# The **Fourier Neural Operator** utilizes the **Fourier transform** in the processor to perform global convolutions. This enables the operator to capture long-range dependencies efficiently. FNOs are particularly useful for problems with periodic data or problems where global patterns and interactions are important.
+#
+# - **Fourier Neural Operator (FNO)**:
+# The **Fourier Neural Operator** utilizes the **Fourier transform** in the processor to perform global convolutions. This enables the operator to capture long-range dependencies efficiently. FNOs are particularly useful for problems with periodic data or problems where global patterns and interactions are important.
# ➤ [Learn more about FNO](https://mathlab.github.io/PINA/_rst/model/fourier_neural_operator.html).
-#
-# - **Graph Neural Operator (GNO)**:
-# The **Graph Neural Operator** leverages **Graph Neural Networks (GNNs)** to exchange information between nodes, enabling the operator to perform convolutions on unstructured domains, such as graphs or meshes. GNOs are especially useful for problems that naturally involve irregular data, such as graph-based datasets or data on non-Euclidean spaces.
+#
+# - **Graph Neural Operator (GNO)**:
+# The **Graph Neural Operator** leverages **Graph Neural Networks (GNNs)** to exchange information between nodes, enabling the operator to perform convolutions on unstructured domains, such as graphs or meshes. GNOs are especially useful for problems that naturally involve irregular data, such as graph-based datasets or data on non-Euclidean spaces.
# ➤ [Learn more about GNO](https://mathlab.github.io/PINA/_rst/model/graph_neural_operator.html).
-#
-# - **Deep Operator Network (DeepONet)**:
+#
+# - **Deep Operator Network (DeepONet)**:
# **DeepONet** is a variant of Neural Operators designed to solve operator equations by learning mappings between input and output functions. Unlike other Neural Operators, **DeepONet** does not use the typical encoder-processor-decoder structure. Instead, it uses two distinct neural networks:
-#
+#
# 1. **Branch Network**: Takes the **function inputs** (e.g., $u(x)$) and learns a feature map of the input function.
# 2. **Trunk Network**: Takes the **spatial locations** (e.g., $x$) and maps them to the output space.
-#
-# The output of **DeepONet** is the combination of these two networks' outputs, which together provide the mapping from the input function to the output function.
+#
+# The output of **DeepONet** is the combination of these two networks' outputs, which together provide the mapping from the input function to the output function.
# ➤ [Learn more about DeepONet](https://mathlab.github.io/PINA/_rst/model/deeponet.html).
-#
+#
# In this tutorial we will focus on Neural Operator which follow the Encoder - Processor - Decoder structure, which we call *Kernel* Neural Operator. Implementing kernel neural Operators in PINA is very simple, you just need to use the `KernelNeuralOperator` API.
-#
+#
# ### KernelNeuralOperator API
-# The `KernelNeuralOperator` API requires three parameters:
-#
+# The `KernelNeuralOperator` API requires three parameters:
+#
# 1. `lifting_operator`: a `torch.nn.Module` apping the input to its hidden dimension (Encoder).
-#
+#
# 2. `integral_kernels`: a `torch.nn.Module` representing the integral kernels mapping each hidden representation to the next one.
-#
+#
# 3. `projection_operator`: a `torch.nn.Module` representing the hidden representation to the output function.
-#
+#
# To construct the kernel, you can use the Neural Operator Blocks available in PINA (see [here](https://mathlab.github.io/PINA/_rst/_code.html#blocks)) or implement you own one! Let's build a simple FNO using the `FourierBlock1D`. In particular we will:
-#
+#
# 1. Define the encoder, a simple linear layer mapping the input dimension to the hidden dimension
# 2. Define the decoder, two linear layers mapping the hidden dimension to 128 and back to the input dimension
# 3. Define the processor, a two layer Fourier block with a specific hidden dimension.
# 4. Combine the encoder-processor-decoder using the `KernelNeuralOperator` API to create the `model`.
-#
+#
# In[23]:
@@ -236,9 +235,9 @@ def forward(self, x):
# Done! Let's now solve the Neural Operator problem. The problem we will define is a basic `SupervisedProblem`, and we will use the `SupervisedSolver` to train the Neural Operator.
-#
+#
# > **👉 We have a dedicated [tutorial](https://mathlab.github.io/PINA/tutorial16/tutorial.html) to teach how to build a Problem from scratch — have a look if you're interested!**
-#
+#
# > **👉 We have a dedicated [tutorial](http://mathlab.github.io/PINA/_rst/tutorials/tutorial18/tutorial.html) for an overview of Solvers in PINA — have a look if you're interested!**
# In[ ]:
@@ -265,7 +264,7 @@ def forward(self, x):
# ## Visualizing the Predictions
-#
+#
# As we can see, we have achieved a very low MSE, even after training for only one epoch. Now, we will visualize the results in the same way as we did previously:
# In[30]:
@@ -288,15 +287,15 @@ def forward(self, x):
# Nice! We can see that the network is correctly learning the solution operator and it was very simple!
-#
+#
# ## What's Next?
-#
+#
# Congratulations on completing the introductory tutorial on Neural Operators! Now that you have a solid foundation, here are a few directions you can explore:
-#
+#
# 1. **Experiment with Training Duration & Network Architecture** — Try different training durations and tweak the network architecture to optimize performance. Choose different integral kernels and see how the results vary.
-#
+#
# 2. **Explore Other Models in `pina.model`** — Check out other models available in `pina.model` or design your own custom PyTorch module to suit your needs. What about trying a `DeepONet`?
-#
+#
# 3. **...and many more!** — The possibilities are vast! Continue experimenting with advanced configurations, solvers, and features in PINA. For example, consider incorporating physics-informed terms during training to enhance model generalization.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial22/tutorial.ipynb b/tutorials/tutorial22/tutorial.ipynb
index 6828b96e8..8bf8821c0 100644
--- a/tutorials/tutorial22/tutorial.ipynb
+++ b/tutorials/tutorial22/tutorial.ipynb
@@ -52,6 +52,7 @@
"import matplotlib.pyplot as plt\n",
"\n",
"import warnings\n",
+ "\n",
"warnings.filterwarnings(\"ignore\")\n",
"\n",
"from pina import Trainer\n",
@@ -302,7 +303,7 @@
" if i != len(self.decoder_convs) - 1:\n",
" x = self.act(x)\n",
" return x\n",
- " \n",
+ "\n",
" def forward(self, data):\n",
" z = self.encode(data)\n",
" return self.decode(z, decoding_graph=data)"
@@ -356,8 +357,8 @@
" bottleneck=8,\n",
" input_size=1352,\n",
" ffn=200,\n",
- " act=torch.nn.ELU\n",
- ")\n"
+ " act=torch.nn.ELU,\n",
+ ")"
]
},
{
@@ -447,9 +448,11 @@
"metadata": {},
"outputs": [],
"source": [
- "latent_representations = torch.stack(\n",
- " [autoencoder.encode(g) for g in graphs], dim=0\n",
- ").squeeze().detach()"
+ "latent_representations = (\n",
+ " torch.stack([autoencoder.encode(g) for g in graphs], dim=0)\n",
+ " .squeeze()\n",
+ " .detach()\n",
+ ")"
]
},
{
diff --git a/tutorials/tutorial22/tutorial.py b/tutorials/tutorial22/tutorial.py
index 801942207..fd5885493 100644
--- a/tutorials/tutorial22/tutorial.py
+++ b/tutorials/tutorial22/tutorial.py
@@ -2,15 +2,15 @@
# coding: utf-8
# # Tutorial: Reduced Order Model with Graph Neural Networks
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial22/tutorial.ipynb)
-#
-#
+#
+#
# > ##### ⚠️ ***Before starting:***
# > We assume you are already familiar with the concepts covered in the [Data Structure for SciML](https://mathlab.github.io/PINA/tutorial19/tutorial.html) tutorial. If not, we strongly recommend reviewing them before exploring this advanced topic.
-#
+#
# In this tutorial, we will demonstrate a typical use case of **PINA** for Reduced Order Modelling using Graph Convolutional Neural Network. The tutorial is largely inspired by the paper [A graph convolutional autoencoder approach to model order reduction for parametrized PDEs](https://www.sciencedirect.com/science/article/pii/S0021999124000111).
-#
+#
# Let's start by importing the useful modules:
# In[1]:
@@ -25,7 +25,9 @@
IN_COLAB = False
if IN_COLAB:
get_ipython().system('pip install "pina-mathlab[tutorial]"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial22/holed_poisson.pt" -O "holed_poisson.pt"')
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial22/holed_poisson.pt" -O "holed_poisson.pt"'
+ )
import torch
from torch import nn
@@ -47,24 +49,23 @@
from pina.solver import ReducedOrderModelSolver
from pina.problem.zoo import SupervisedProblem
-
# ## Data Generation
-#
+#
# In this tutorial, we will focus on solving the parametric **Poisson** equation, a linear PDE. The equation is given by:
-#
+#
# $$
# \begin{cases}
# -\frac{1}{10}\Delta u = 1, &\Omega(\boldsymbol{\mu}),\\
# u = 0, &\partial \Omega(\boldsymbol{\mu}).
# \end{cases}
# $$
-#
-# In this equation, $\Omega(\boldsymbol{\mu}) = [0, 1]\times[0,1] \setminus [\mu_1, \mu_2]\times[\mu_1+0.3, \mu_2+0.3]$ represents the spatial domain characterized by a parametrized hole defined via $\boldsymbol{\mu} = (\mu_1, \mu_2) \in \mathbb{P} = [0.1, 0.6]\times[0.1, 0.6]$. Thus, the geometrical parameters define the left bottom corner of a square obstacle of dimension $0.3$. The problem is coupled with homogenous Dirichlet conditions on both internal and external boundaries. In this setting, $u(\mathbf{x}, \boldsymbol{\mu})\in \mathbb{R}$ is the value of the function $u$ at each point in space for a specific parameter $\boldsymbol{\mu}$.
-#
-# We have already generated data for different parameters. The dataset is obtained via $\mathbb{P}^1$ FE method, and an equispaced sampling with 11 points in each direction of the parametric space.
-#
+#
+# In this equation, $\Omega(\boldsymbol{\mu}) = [0, 1]\times[0,1] \setminus [\mu_1, \mu_2]\times[\mu_1+0.3, \mu_2+0.3]$ represents the spatial domain characterized by a parametrized hole defined via $\boldsymbol{\mu} = (\mu_1, \mu_2) \in \mathbb{P} = [0.1, 0.6]\times[0.1, 0.6]$. Thus, the geometrical parameters define the left bottom corner of a square obstacle of dimension $0.3$. The problem is coupled with homogenous Dirichlet conditions on both internal and external boundaries. In this setting, $u(\mathbf{x}, \boldsymbol{\mu})\in \mathbb{R}$ is the value of the function $u$ at each point in space for a specific parameter $\boldsymbol{\mu}$.
+#
+# We have already generated data for different parameters. The dataset is obtained via $\mathbb{P}^1$ FE method, and an equispaced sampling with 11 points in each direction of the parametric space.
+#
# The goal is to build a Reduced Order Model that given a new parameter $\boldsymbol{\mu}^*$, is able to get the solution $u$ *for any discretization* $\mathbf{x}$. To this end, we will train a Graph Convolutional Autoencoder Reduced Order Model (GCA-ROM), as presented in [A graph convolutional autoencoder approach to model order reduction for parametrized PDEs](https://www.sciencedirect.com/science/article/pii/S0021999124000111). We will cover the architecture details later, but for now, let’s start by importing the data.
-#
+#
# **Note:**
# The numerical integration is obtained using a finite element method with the [RBniCS library](https://www.rbnicsproject.org/).
@@ -93,42 +94,42 @@
# ## Graph-Based Reduced Order Modeling
-#
+#
# In this problem, the geometry of the spatial domain is **unstructured**, meaning that classical grid-based methods (e.g., CNNs) are not well suited. Instead, we represent the mesh as a **graph**, where nodes correspond to spatial degrees of freedom and edges represent connectivity. This makes **Graph Neural Networks (GNNs)**, and in particular **Graph Convolutional Networks (GCNs)**, a natural choice to process the data.
-#
+#
#
#  #
#
-#
+#
# To reduce computational complexity while preserving accuracy, we employ a **Reduced Order Modeling (ROM)** strategy (see picture above). The idea is to map high-dimensional simulation data $u(\mathbf{x}, \boldsymbol{\mu})$ to a compact **latent space** using a **graph convolutional encoder**, and then reconstruct it back via a **decoder** (offline phase). The latent representation captures the essential features of the solution manifold. Moreover, we can learn a **parametric map** $\mathcal{M}$ from the parameter space $\boldsymbol{\mu}$ directly into the latent space, enabling predictions for new unseen parameters.
-#
+#
# Formally, the autoencoder consists of an **encoder** $\mathcal{E}$, a **decoder** $\mathcal{D}$, and a **parametric mapping** $\mathcal{M}$:
# $$
-# z = \mathcal{E}(u(\mathbf{x}, \boldsymbol{\mu})),
+# z = \mathcal{E}(u(\mathbf{x}, \boldsymbol{\mu})),
# \quad
# \hat{u}(\mathbf{x}, \boldsymbol{\mu}) = \mathcal{D}(z),
# \quad
# \hat{z} = \mathcal{M}(\boldsymbol{\mu}),
# $$
# where $z \in \mathbb{R}^r$ is the latent representation with $r \ll N$ (the number of degrees of freedom) and the **hat notation** ($\hat{u}, \hat{z}$) indicates *learned or approximated quantities*.
-#
+#
# The training objective balances two terms:
# 1. **Reconstruction loss**: ensuring the autoencoder can faithfully reconstruct $u$ from $z$.
# 2. **Latent consistency loss**: enforcing that the parametric map $\mathcal{M}(\boldsymbol{\mu})$ approximates the encoder’s latent space.
-#
+#
# The combined loss function is:
# $$
-# \mathcal{L}(\theta) = \frac{1}{N} \sum_{i=1}^N
-# \big\| u(\mathbf{x}, \boldsymbol{\mu}_i) -
-# \mathcal{D}\!\big(\mathcal{E}(u(\mathbf{x}, \boldsymbol{\mu}_i))\big)
+# \mathcal{L}(\theta) = \frac{1}{N} \sum_{i=1}^N
+# \big\| u(\mathbf{x}, \boldsymbol{\mu}_i) -
+# \mathcal{D}\!\big(\mathcal{E}(u(\mathbf{x}, \boldsymbol{\mu}_i))\big)
# \big\|_2^2
# \;+\; \frac{1}{N} \sum_{i=1}^N
# \big\| \mathcal{E}(u(\mathbf{x}, \boldsymbol{\mu}_i)) - \mathcal{M}(\boldsymbol{\mu}_i) \big\|_2^2.
# $$
# This framework leverages the expressive power of GNNs for unstructured geometries and the efficiency of ROMs for handling parametric PDEs.
-#
+#
# We will now build the autoencoder network, which is a `nn.Module` with two methods: `encode` and `decode`.
-#
+#
# In[3]:
@@ -196,17 +197,17 @@ def decode(self, z, decoding_graph=None):
# Great! We now need to build the graph structure (a PyTorch Geometric `Data` object) from the numerical solver outputs.
-#
+#
# The solver provides the solution values $u(\mathbf{x}, \boldsymbol{\mu})$ for each parameter instance $\boldsymbol{\mu}$, along with the node coordinates $(x, y)$ of the unstructured mesh. Because the geometry is not defined on a regular grid, we naturally represent the mesh as a graph:
-#
-# - **Nodes** correspond to spatial points in the mesh. Each node stores the **solution value** $u$ at that point as a feature.
+#
+# - **Nodes** correspond to spatial points in the mesh. Each node stores the **solution value** $u$ at that point as a feature.
# - **Edges** represent mesh connectivity. For each edge, we compute:
-# - **Edge attributes**: the relative displacement vector between the two nodes.
-# - **Edge weights**: the Euclidean distance between the connected nodes.
+# - **Edge attributes**: the relative displacement vector between the two nodes.
+# - **Edge weights**: the Euclidean distance between the connected nodes.
# - **Positions** store the physical $(x, y)$ coordinates of the nodes.
-#
+#
# For each parameter realization $\boldsymbol{\mu}_i$, we therefore construct a PyTorch Geometric `Data` object:
-#
+#
# In[4]:
@@ -237,11 +238,11 @@ def decode(self, z, decoding_graph=None):
# ## Training with PINA
-#
-# Everything is now ready! We can use **PINA** to train the model, following the workflow from previous tutorials. First, we need to define the problem. In this case, we will use the [`SupervisedProblem`](https://mathlab.github.io/PINA/_rst/problem/zoo/supervised_problem.html#module-pina.problem.zoo.supervised_problem), which expects:
-#
-# - **Input**: the parameter tensor $\boldsymbol{\mu}$ describing each scenario.
-# - **Output**: the corresponding graph structure (PyTorch Geometric `Data` object) that we aim to reconstruct.
+#
+# Everything is now ready! We can use **PINA** to train the model, following the workflow from previous tutorials. First, we need to define the problem. In this case, we will use the [`SupervisedProblem`](https://mathlab.github.io/PINA/_rst/problem/zoo/supervised_problem.html#module-pina.problem.zoo.supervised_problem), which expects:
+#
+# - **Input**: the parameter tensor $\boldsymbol{\mu}$ describing each scenario.
+# - **Output**: the corresponding graph structure (PyTorch Geometric `Data` object) that we aim to reconstruct.
# In[5]:
@@ -249,9 +250,9 @@ def decode(self, z, decoding_graph=None):
problem = SupervisedProblem(params, graphs)
-# Next, we build the **autoencoder network** and the **interpolation network**.
-#
-# - The **Graph Convolutional Autoencoder (GCA)** encodes the high-dimensional graph data into a compact latent space and reconstructs the graphs from this latent representation.
+# Next, we build the **autoencoder network** and the **interpolation network**.
+#
+# - The **Graph Convolutional Autoencoder (GCA)** encodes the high-dimensional graph data into a compact latent space and reconstructs the graphs from this latent representation.
# - The **interpolation network** (or parametric map) learns to map a new parameter $\boldsymbol{\mu}^*$ directly into the latent space, enabling the model to predict solutions for unseen parameter instances without running the full encoder.
# In[6]:
@@ -269,11 +270,11 @@ def decode(self, z, decoding_graph=None):
)
-# Finally, we will use the [`ReducedOrderModelSolver`](https://mathlab.github.io/PINA/_rst/solver/supervised_solver/reduced_order_model.html#pina.solver.supervised_solver.reduced_order_model.ReducedOrderModelSolver) to perform the training, as discussed earlier.
-#
-# This solver requires two components:
-# - an **interpolation network**, which maps parameters $\boldsymbol{\mu}$ to the latent space, and
-# - a **reduction network**, which in our case is the **autoencoder** that compresses and reconstructs the graph data.
+# Finally, we will use the [`ReducedOrderModelSolver`](https://mathlab.github.io/PINA/_rst/solver/supervised_solver/reduced_order_model.html#pina.solver.supervised_solver.reduced_order_model.ReducedOrderModelSolver) to perform the training, as discussed earlier.
+#
+# This solver requires two components:
+# - an **interpolation network**, which maps parameters $\boldsymbol{\mu}$ to the latent space, and
+# - a **reduction network**, which in our case is the **autoencoder** that compresses and reconstructs the graph data.
# In[7]:
@@ -319,8 +320,8 @@ def forward(self, output, target):
# Once the model is trained, we can test the reconstruction by following two steps:
-#
-# 1. **Interpolate**: Use the `interpolation_network` to map a new parameter $\boldsymbol{\mu}^*$ to the latent space.
+#
+# 1. **Interpolate**: Use the `interpolation_network` to map a new parameter $\boldsymbol{\mu}^*$ to the latent space.
# 2. **Decode**: Pass the interpolated latent vector through the autoencoder (`reduction_network`) to reconstruct the corresponding graph data.
# In[9]:
@@ -392,18 +393,18 @@ def forward(self, output, target):
plt.show()
-# Nice! We can see that the network is correctly learning the solution operator, and the workflow was very straightforward.
-#
+# Nice! We can see that the network is correctly learning the solution operator, and the workflow was very straightforward.
+#
# You may notice that the network outputs are not as smooth as the actual solution. Don’t worry — training for longer (e.g., ~5000 epochs) will produce a smoother, more accurate reconstruction.
-#
+#
# ## What's Next?
-#
+#
# Congratulations on completing the introductory tutorial on **Graph Convolutional Reduced Order Modeling**! Now that you have a solid foundation, here are a few directions to explore:
-#
+#
# 1. **Experiment with Training Duration** — Try different training durations and adjust the network architecture to optimize performance. Explore different integral kernels and observe how the results vary.
-#
+#
# 2. **Explore Physical Constraints** — Incorporate physics-informed terms or constraints during training to improve model generalization and ensure physically consistent predictions.
-#
+#
# 3. **...and many more!** — The possibilities are vast! Continue experimenting with advanced configurations, solvers, and features in PINA.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial23/tutorial.py b/tutorials/tutorial23/tutorial.py
index 24bb8aa9a..160efbe74 100644
--- a/tutorials/tutorial23/tutorial.py
+++ b/tutorials/tutorial23/tutorial.py
@@ -2,15 +2,15 @@
# coding: utf-8
# # Tutorial: Data-driven System Identification with SINDy
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial23/tutorial.ipynb)
-#
-#
+#
+#
# > ##### ⚠️ ***Before starting:***
# > We assume you are already familiar with the concepts covered in the [Getting started with PINA](https://mathlab.github.io/PINA/_tutorial.html#getting-started-with-pina) tutorial. If not, we strongly recommend reviewing them before exploring this advanced topic.
-#
+#
# In this tutorial, we will demonstrate a typical use case of **PINA** for Data-driven system identification using SINDy. The tutorial is largely inspired by the paper [Discovering governing equations from data by sparse identification of nonlinear dynamical systems](dx.doi.org/10.1073/pnas.1517384113).
-#
+#
# Let's start by importing the useful modules:
# In[1]:
@@ -41,23 +41,22 @@
from pina.optim import TorchOptimizer
from pina.model import SINDy
-
# ## Data generation
# In this tutorial, we'll focus on the **identification** of a dynamical system starting only from a finite set of **snapshots**.
# More precisely, we'll assume that the dynamics is governed by dynamical system written as follows:
# $$\dot{\boldsymbol{x}}(t)=\boldsymbol{f}(\boldsymbol{x}(t)),$$
# along with suitable initial conditions.
# For simplicity, we'll omit the argument of $\boldsymbol{x}$ from this point onward.
-#
+#
# Since $\boldsymbol{f}$ is unknown, we want to model it.
# While neural networks could be used to find an expression for $\boldsymbol{f}$, in certain contexts - for instance, to perform long-horizon forecasting - it might be useful to have an **explicit** set of equations describing it, which would also allow for a better degree of **interpretability** of our model.
-#
+#
# As a result, we use SINDy (introduced in [this paper](https://www.pnas.org/doi/full/10.1073/pnas.1517384113)), which we'll describe later on.
# Now, instead, we describe the system that is going to be considered in this tutorial: the **Lorenz** system.
-#
+#
# The Lorenz system is a set of three ordinary differential equations and is a simplified model of atmospheric convection.
# It is well-known because it can exhibit chaotic behavior, _i.e._, for given values of the parameters solutions are highly sensitive to small perturbations in the initial conditions, making forecasting extremely challenging.
-#
+#
# Mathematically speaking, we can write the Lorenz equations as
# $$
# \begin{cases}
@@ -67,9 +66,9 @@
# \end{cases}
# $$
# With $\sigma = 10,\, \rho = 28$, and $\beta=8/3$, the solutions trace out the famous butterfly-shaped Lorenz attractor.
-#
+#
# With the following lines of code, we just generate the dataset for SINDy and plot some trajectories.
-#
+#
# **Disclaimer**: of course, here we use the equations defining the Lorenz system just to generate the data.
# If we had access to the dynamical term $\boldsymbol{f}$, there would be no need to use SINDy.
@@ -126,24 +125,24 @@ def plot_n_conditions(X, n_to_plot):
# \dot{x}_i = f_i(\boldsymbol{x}) = \sum_{k}\Theta(\boldsymbol{x})_{k}\xi_{k,i},
# $$
# with $\boldsymbol{\xi}_i\in\mathbb{R}^r$ a vector of **coefficients** telling us which terms are active in the expression of $f_i$.
-#
+#
# Since we are in a supervised setting, we assume that we have at our disposal the snapshot matrix $\boldsymbol{X}$ and a matrix $\dot{\boldsymbol{X}}$ containing time **derivatives** at the corresponding time instances.
# Then, we can just impose that the previous relation holds on the data at our disposal.
# That is, our optimization problem will read as follows:
# $$
# \min_{\boldsymbol{\Xi}}\|\dot{\boldsymbol{X}}-\Theta(\boldsymbol{X})\boldsymbol{\Xi}\|_2^2.
# $$
-#
+#
# Notice, however, that the solution to the previous equation might not be **sparse**, as there might be many non-zero terms in it.
# In practice, many physical systems are described by a parsimonious and **interpretable** set of equations.
# Thus, we also impose a $L^1$ **penalization** on the model weights, encouraging them to be small in magnitude and trying to enforce sparsity.
# The final loss is then expressed as
-#
+#
# $$
# \min_{\boldsymbol{\Xi}}\bigl(\|\dot{\boldsymbol{X}}-\Theta(\boldsymbol{X})\boldsymbol{\Xi}\|_2^2 + \lambda\|\boldsymbol{\Xi}\|_1\bigr),
# $$
# with $\lambda\in\mathbb{R}^+$ a hyperparameter.
-#
+#
# Let us begin by computing the time derivatives of the data.
# Of course, usually we do not have access to the exact time derivatives of the system, meaning that $\dot{\boldsymbol{X}}$ needs to be **approximated**.
# Here we do it using a simple Finite Difference (FD) scheme, but [more sophisticated ideas](https://arxiv.org/abs/2505.16058) could be considered.
@@ -195,9 +194,9 @@ def plot_n_conditions(X, n_to_plot):
# ## Training with PINA
# We are now ready to train our model! We can use **PINA** to train the model, following the workflow from previous tutorials.
-# First, we need to define the problem. In this case, we will use the [`SupervisedProblem`](https://mathlab.github.io/PINA/_rst/problem/zoo/supervised_problem.html#module-pina.problem.zoo.supervised_problem), which expects:
-#
-# - **Input**: the state variables tensor $\boldsymbol{X}$ containing all the collected snapshots.
+# First, we need to define the problem. In this case, we will use the [`SupervisedProblem`](https://mathlab.github.io/PINA/_rst/problem/zoo/supervised_problem.html#module-pina.problem.zoo.supervised_problem), which expects:
+#
+# - **Input**: the state variables tensor $\boldsymbol{X}$ containing all the collected snapshots.
# - **Output**: the corresponding time derivatives $\dot{\boldsymbol{X}}$.
# In[6]:
@@ -210,7 +209,7 @@ def plot_n_conditions(X, n_to_plot):
# Finally, we will use the `SupervisedSolver` to perform the training as we're dealing with a supervised problem.
-#
+#
# Recall that we should use $L^1$-regularization on the model's weights to ensure sparsity. For the ease of implementation, we adopt $L^2$ regularization, which is less common in SINDy literature but will suffice in our case.
# Additionally, more refined strategies could be used, for instance pruning coefficients below a certain **threshold** at every fixed number of epochs, but here we avoid further complications.
@@ -246,11 +245,11 @@ def plot_n_conditions(X, n_to_plot):
# Now we'll print the identified equations and compare them with the original ones.
-#
+#
# Before going on, we underline that after training there might be many coefficients that are small, yet still non-zero.
# It is common for SINDy practitioners to interpret these coefficients as noise in the model and prune them.
# This is typically done by fixing a threshold $\tau\in\mathbb{R}^+$ and setting to $0$ all those $\xi_{i,j}$ such that $|\xi_{i,j}|<\tau$.
-#
+#
# In the following cell, we also define a function to print the identified model.
# In[9]:
@@ -299,9 +298,9 @@ def print_coefficients(model, function_names, tau, vars=None):
# \dot{z}=-\frac{8}{3} z+xy.
# \end{cases}
# $$
-#
+#
# That's a good result, especially considering that we did not perform tuning on the weight decay hyperparameter $\lambda$ and did not really care much about other optimization parameters.
-#
+#
# Let's plot a few trajectories!
# In[10]:
@@ -328,14 +327,14 @@ def SINDy_equations(x, t): # we need a numpy array for odeint
# Great! We can see that the qualitative behavior of the system is really close to the real one.
-#
+#
# ## What's next?
# Congratulations on completing the introductory tutorial on **Data-driven System Identification with SINDy**! Now that you have a solid foundation, here are a few directions to explore:
-#
-# 1. **Experiment with Dimensionality Reduction techniques** — Try to combine SINDy with different reductions techniques such as POD or autoencoders - or both of them, as done [here](https://www.sciencedirect.com/science/article/abs/pii/S0045793025003019).
-#
+#
+# 1. **Experiment with Dimensionality Reduction techniques** — Try to combine SINDy with different reductions techniques such as POD or autoencoders - or both of them, as done [here](https://www.sciencedirect.com/science/article/abs/pii/S0045793025003019).
+#
# 2. **Study Parameterized Systems** — Write your own SINDy model for parameterized problems.
-#
+#
# 3. **...and many more!** — The possibilities are vast! Continue experimenting with advanced configurations, solvers, and features in PINA.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial24/tutorial.py b/tutorials/tutorial24/tutorial.py
index 8dba9990b..1eb26cd7c 100644
--- a/tutorials/tutorial24/tutorial.py
+++ b/tutorials/tutorial24/tutorial.py
@@ -2,15 +2,15 @@
# coding: utf-8
# # Tutorial: Advection Equation with data driven DeepONet
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial24/tutorial.ipynb)
-#
-#
+#
+#
# > ##### ⚠️ ***Before starting:***
# > We assume you are already familiar with the concepts covered in the [Getting started with PINA](https://mathlab.github.io/PINA/_tutorial.html#getting-started-with-pina) tutorials. If not, we strongly recommend reviewing them before exploring this advanced topic.
-#
+#
# In this tutorial, we demonstrate how to solve the advection operator learning problem using `DeepONet`. We follow the original formulation of Lu *et al.* in [*DeepONet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operator*](https://arxiv.org/abs/1910.03193).
-#
+#
# We begin by importing the necessary modules.
# In[1]:
@@ -27,10 +27,18 @@
get_ipython().system('pip install "pina-mathlab[tutorial]"')
# get the data
get_ipython().system('mkdir "data"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial24/data/advection_input_testing.pt" -O "data/advection_input_testing.pt"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial24/data/advection_input_training.pt" -O "data/advection_input_training.pt"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial24/data/advection_output_testing.pt" -O "data/advection_output_testing.pt"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial24/data/advection_output_training.pt" -O "data/advection_output_training.pt"')
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial24/data/advection_input_testing.pt" -O "data/advection_input_testing.pt"'
+ )
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial24/data/advection_input_training.pt" -O "data/advection_input_training.pt"'
+ )
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial24/data/advection_output_testing.pt" -O "data/advection_output_testing.pt"'
+ )
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial24/data/advection_output_training.pt" -O "data/advection_output_training.pt"'
+ )
import matplotlib.pyplot as plt
import torch
@@ -47,31 +55,31 @@
# ## Advection problem and data preparation
-#
+#
# We consider the 1D advection equation
# $$
-# \frac{\partial u}{\partial t} + \frac{\partial u}{\partial x} = 0,
+# \frac{\partial u}{\partial t} + \frac{\partial u}{\partial x} = 0,
# \quad x \in [0,2], \; t \in [0,1],
# $$
# with periodic boundary conditions. The initial condition is chosen as a Gaussian pulse centered at a random location
# $\mu \sim U(0.05, 1)$ and with variance $\sigma^2 = 0.02$:
# $$
-# u_0(x) = \frac{1}{\sqrt{\pi\sigma^2}} e^{-\frac{(x - \mu)^2}{2\sigma^2}},
+# u_0(x) = \frac{1}{\sqrt{\pi\sigma^2}} e^{-\frac{(x - \mu)^2}{2\sigma^2}},
# \quad x \in [0,2].
# $$
-#
+#
# Our goal is to learn the operator
# $$
# \mathcal{G}: u_0(x) \mapsto u(x, t = \delta) = u_0(x - \delta),
# $$
-# with $\delta = 0.5$ for this tutorial. In practice, this means learning a mapping from the initial condition to the solution at a fixed later time.
+# with $\delta = 0.5$ for this tutorial. In practice, this means learning a mapping from the initial condition to the solution at a fixed later time.
# The dataset therefore consists of trajectories where inputs are initial profiles and outputs are the same profiles shifted by $\delta$.
-#
+#
# The data has shape `[T, Nx, D]`, where:
# - `T` — number of trajectories (100 for training, 1000 for testing),
# - `Nx` — number of spatial grid points (fixed at 100),
# - `D = 1` — single scalar field value `u`.
-#
+#
# We now load the dataset and visualize sample trajectories.
# In[2]:
@@ -121,24 +129,24 @@
# Great — we have generated a traveling wave and visualized a few samples. Next, we will use this data to train a `DeepONet`.
-#
+#
# ## DeepONet
-#
+#
# The standard `DeepONet` architecture consists of two subnetworks: a **branch** network and a **trunk** network (see figure below).
-#
+#
#
#  #
#
# Image source: Moya & Lin (2022)
#
-#
+#
# In our setting:
# - The **branch network** receives the initial condition of each trajectory, with input shape `[B, Nx]` — where `B` is the batch size and `Nx` the spatial discretization points of the field at \( t = 0 \).
# - The **trunk network** takes input of shape `[B, 1]`, corresponding to the location at which we evaluate the solution (in this 1D case, the spatial coordinate).
-#
+#
# Together, these networks learn the mapping from the initial field to the solution at a later time.
-#
+#
# We now define and train the model for the advection problem.
# In[4]:
@@ -181,9 +189,9 @@ def forward(self, x):
# The `TrunkNet` is implemented as a standard `FeedForward` network with a slightly modified `forward` method. In this case, the trunk network simply outputs a tensor filled with the value \(0.5\), repeated for each trajectory — corresponding to evaluating the solution at time \(t = 0.5\).
-#
+#
# The `BranchNet` is also a `FeedForward` network, but its `forward` pass first flattens the input along the last dimension. This produces a vector of length `Nx`, representing the sampled initial condition at the sensor locations.
-#
+#
# With both subnetworks defined, we can now instantiate the DeepONet model using the `DeepONet` class from `pina.model`.
# In[6]:
@@ -215,7 +223,7 @@ def forward(self, x):
# The aggregation and reduction functions combine the outputs of the branch and trunk networks. In this example, their outputs are multiplied element-wise, and no reduction is applied — meaning the final output has the same dimensionality as each network’s output.
-#
+#
# We train the model using a `SupervisedSolver` with an `MSE` loss. Below, we first define the solver and then the trainer used to run the optimization.
# In[ ]:
@@ -269,7 +277,7 @@ def forward(self, x):
plt.show()
-# As we can see, they are barely indistinguishable. To better understand the difference, we now plot the residuals, i.e. the difference of the exact solution and the predicted one.
+# As we can see, they are barely indistinguishable. To better understand the difference, we now plot the residuals, i.e. the difference of the exact solution and the predicted one.
# In[10]:
@@ -288,17 +296,17 @@ def forward(self, x):
# ## What's Next?
-#
+#
# We have seen a simple example of using `DeepONet` to learn the advection operator. This only scratches the surface of what neural operators can do. Here are some suggested directions to continue your exploration:
-#
+#
# 1. **Train on more complex PDEs**: Extend beyond the advection equation to more challenging operators, such as diffusion or nonlinear conservation laws.
-#
+#
# 2. **Increase training scope**: Experiment with larger datasets, deeper networks, and longer training schedules to unlock the full potential of neural operator learning.
-#
+#
# 3. **Generalize to the full advection operator**: Train the model to learn the general operator $\mathcal{G}_t: u_0(x) \mapsto u(x,t) = u_0(x - t)$ so the network predicts solutions for arbitrary times, not just a single fixed horizon.
-#
+#
# 4. **Investigate architectural variations**: Compare different operator learning architectures (e.g., Fourier Neural Operators, Physics-Informed DeepONets) to see how they perform on similar problems.
-#
+#
# 5. **...and much more!**: From adding noise robustness to testing on real scientific datasets, the space of possibilities is wide open.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial3/tutorial.py b/tutorials/tutorial3/tutorial.py
index d01534a79..5f7d7c03b 100644
--- a/tutorials/tutorial3/tutorial.py
+++ b/tutorials/tutorial3/tutorial.py
@@ -2,11 +2,11 @@
# coding: utf-8
# # Tutorial: Applying Hard Constraints in PINNs to solve the Wave Problem
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial3/tutorial.ipynb)
-#
+#
# In this tutorial, we will present how to solve the wave equation using **hard constraint Physics-Informed Neural Networks (PINNs)**. To achieve this, we will build a custom `torch` model and pass it to the **PINN solver**.
-#
+#
# First of all, some useful imports.
# In[ ]:
@@ -37,10 +37,10 @@
warnings.filterwarnings("ignore")
-# ## The problem definition
-#
+# ## The problem definition
+#
# The problem is described by the following system of partial differential equations (PDEs):
-#
+#
# \begin{equation}
# \begin{cases}
# \Delta u(x,y,t) = \frac{\partial^2}{\partial t^2} u(x,y,t) \quad \text{in } D, \\\\
@@ -48,9 +48,9 @@
# u(x, y, t) = 0 \quad \text{on } \Gamma_1 \cup \Gamma_2 \cup \Gamma_3 \cup \Gamma_4,
# \end{cases}
# \end{equation}
-#
+#
# Where:
-#
+#
# - $D$ is a square domain $[0, 1]^2$.
# - $\Gamma_i$, where $i = 1, \dots, 4$, are the boundaries of the square where Dirichlet conditions are applied.
# - The velocity in the standard wave equation is fixed to $1$.
@@ -101,13 +101,13 @@ def solution(self, pts):
# ## Hard Constraint Model
-#
+#
# Once the problem is defined, a **torch** model is needed to solve the PINN. While **PINA** provides several pre-implemented models, users have the option to build their own custom model using **torch**. The hard constraint we impose is on the boundary of the spatial domain. Specifically, the solution is written as:
-#
+#
# $$ u_{\rm{pinn}} = xy(1-x)(1-y)\cdot NN(x, y, t), $$
-#
+#
# where $NN$ represents the neural network output. This neural network takes the spatial coordinates $x$, $y$, and time $t$ as input and provides the unknown field $u$. By construction, the solution is zero at the boundaries.
-#
+#
# The residuals of the equations are evaluated at several sampling points (which the user can manipulate using the `discretise_domain` method). The loss function minimized by the neural network is the sum of the residuals.
# In[3]:
@@ -233,13 +233,13 @@ def plot_solution(solver, time):
# The results are not ideal, and we can clearly see that as time progresses, the solution deteriorates. Can we do better?
-#
+#
# One valid approach is to impose the initial condition as a hard constraint as well. Specifically, we modify the solution to:
-#
+#
# $$
# u_{\rm{pinn}} = xy(1-x)(1-y) \cdot NN(x, y, t) \cdot t + \cos(\sqrt{2}\pi t)\sin(\pi x)\sin(\pi y),
# $$
-#
+#
# Now, let us start by building the neural network.
# In[8]:
@@ -319,19 +319,19 @@ def forward(self, x):
# We can now see that the results are much better! This improvement is due to the fact that, previously, the network was not correctly learning the initial condition, which led to a poor solution as time evolved. By imposing the initial condition as a hard constraint, the network is now able to correctly solve the problem.
# ## What's Next?
-#
+#
# Congratulations on completing the two-dimensional Wave tutorial of **PINA**! Now that you’ve got the basics down, there are several directions you can explore:
-#
+#
# 1. **Train the Network for Longer**: Train the network for a longer duration or experiment with different layer sizes to assess the final accuracy.
-#
+#
# 2. **Propose New Types of Hard Constraints in Time**: Experiment with new time-dependent hard constraints, for example:
-#
+#
# $$
# u_{\rm{pinn}} = xy(1-x)(1-y)\cdot NN(x, y, t)(1-\exp(-t)) + \cos(\sqrt{2}\pi t)\sin(\pi x)\sin(\pi y)
# $$
-#
+#
# 3. **Exploit Extrafeature Training**: Apply extrafeature training techniques to improve models from 1 and 2.
-#
+#
# 4. **...and many more!**: The possibilities are endless! Keep experimenting and pushing the boundaries.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial4/tutorial.py b/tutorials/tutorial4/tutorial.py
index ae0004ddf..67680d591 100644
--- a/tutorials/tutorial4/tutorial.py
+++ b/tutorials/tutorial4/tutorial.py
@@ -5,7 +5,7 @@
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial4/tutorial.ipynb)
# In this tutorial, we will show how to use the Continuous Convolutional Filter, and how to build common Deep Learning architectures with it. The implementation of the filter follows the original work [*A Continuous Convolutional Trainable Filter for Modelling Unstructured Data*](https://arxiv.org/abs/2210.13416).
-#
+#
# First of all we import the modules needed for the tutorial:
# In[ ]:
@@ -37,72 +37,72 @@
# ## Tutorial Structure
-#
+#
# The tutorial is structured as follows:
-#
-# - [🔹 Continuous Filter Background](#continuous-filter-background):
+#
+# - [🔹 Continuous Filter Background](#continuous-filter-background):
# Understand how the convolutional filter works and how to use it.
-#
-# - [🔹 Building a MNIST Classifier](#building-a-mnist-classifier):
+#
+# - [🔹 Building a MNIST Classifier](#building-a-mnist-classifier):
# Learn how to build a simple classifier using the MNIST dataset, and how to combine a continuous convolutional layer with a feedforward neural network.
-#
-# - [🔹 Building a Continuous Convolutional Autoencoder](#building-a-continuous-convolutional-autoencoder):
+#
+# - [🔹 Building a Continuous Convolutional Autoencoder](#building-a-continuous-convolutional-autoencoder):
# Explore how to use the continuous filter to work with unstructured data for autoencoding and up-sampling.
-#
+#
# ## Continuous Filter Background
-#
+#
# As reported by the authors in the original paper, in contrast to discrete convolution, **continuous convolution** is mathematically defined as:
-#
+#
# $$
# \mathcal{I}_{\rm{out}}(\mathbf{x}) = \int_{\mathcal{X}} \mathcal{I}(\mathbf{x} + \mathbf{\tau}) \cdot \mathcal{K}(\mathbf{\tau}) d\mathbf{\tau},
# $$
-#
+#
# where:
# - $\mathcal{K} : \mathcal{X} \rightarrow \mathbb{R}$ is the **continuous filter** function,
# - $\mathcal{I} : \Omega \subset \mathbb{R}^N \rightarrow \mathbb{R}$ is the input function.
-#
+#
# The **continuous filter function** is approximated using a **FeedForward Neural Network**, which is **trainable** during the training phase. The way in which the integral is approximated can vary. In the **PINA** framework, we approximate it using a simple sum, as suggested by the authors. Thus, given the points $\{\mathbf{x}_i\}_{i=1}^{n}$ in $\mathbb{R}^N$ mapped onto the filter domain $\mathcal{X}$, we approximate the equation as:
-#
+#
# $$
# \mathcal{I}_{\rm{out}}(\mathbf{\tilde{x}}_i) = \sum_{{\mathbf{x}_i}\in\mathcal{X}} \mathcal{I}(\mathbf{x}_i + \mathbf{\tau}) \cdot \mathcal{K}(\mathbf{x}_i),
# $$
-#
+#
# where $\mathbf{\tau} \in \mathcal{S}$, with $\mathcal{S}$ being the set of available strides, represents the current stride position of the filter. The $\mathbf{\tilde{x}}_i$ points are obtained by taking the **centroid** of the filter position mapped onto the domain $\Omega$.
-#
+#
# ### Working with the Continuous Filter
-#
+#
# From the above definition, what is needed is:
# 1. A **domain** and a **function** defined on that domain (the input),
# 2. A **stride**, corresponding to the positions where the filter needs to be applied (this is the `stride` variable in `ContinuousConv`),
# 3. The **filter's rectangular domain**, which corresponds to the `filter_dim` variable in `ContinuousConv`.
-#
+#
# ### Input Function
-#
+#
# The input function for the continuous filter is defined as a tensor of shape:
-#
+#
# $$[B \times N_{\text{in}} \times N \times D]$$
-#
+#
# where:
# - $B$ is the **batch size**,
# - $N_{\text{in}}$ is the number of input fields,
# - $N$ is the number of points in the mesh,
-# - $D$ is the dimension of the problem.
-#
+# - $D$ is the dimension of the problem.
+#
# In particular:
# - $D$ represents the **number of spatial variables** + 1. The last column must contain the field value. For example, for 2D problems, $D=3$ and the tensor will look like `[first coordinate, second coordinate, field value]`.
# - $N_{\text{in}}$ represents the number of vectorial functions presented. For example, a vectorial function $f = [f_1, f_2]$ will have $N_{\text{in}}=2$.
-#
+#
# #### Example: Input Function for a Vectorial Field
-#
+#
# Let’s see an example to clarify the idea. Suppose we wish to create the function:
-#
+#
# $$
# f(x, y) = [\sin(\pi x) \sin(\pi y), -\sin(\pi x) \sin(\pi y)] \quad (x,y)\in[0,1]\times[0,1]
# $$
-#
+#
# We can do this with a **batch size** equal to 1. This function consists of two components (vectorial field), so $N_{\text{in}}=2$. For each $(x,y)$ pair in the domain $[0,1] \times [0,1]$, we will compute the corresponding field values:
-#
+#
# 1. $\sin(\pi x) \sin(\pi y)$
# 2. $-\sin(\pi x) \sin(\pi y)$
@@ -139,9 +139,9 @@
# ### Stride
-#
+#
# The **stride** is passed as a dictionary `stride` that dictates where the filter should move. Here's an example for the domain $[0,1] \times [0,5]$:
-#
+#
# ```python
# # stride definition
# stride = {"domain": [1, 5],
@@ -155,9 +155,9 @@
# 2. `start`: The starting position of the filter's centroid. In this example, the filter starts at the position $(0, 0)$.
# 3. `jump`: The steps or jumps of the filter’s centroid to the next position. In this example, the filter moves by $(0.1, 0.3)$ along the x and y axes respectively.
# 4. `direction`: The directions of the jumps for each coordinate. A value of 1 indicates the filter moves right, 0 means no movement, and -1 indicates the filter moves left with respect to its current position.
-#
+#
# ### Filter definition
-#
+#
# Now that we have defined the stride, we can move on to construct the continuous filter.
# Let’s assume we want the output to contain only one field, and we will set the filter dimension to be $[0.1, 0.1]$.
@@ -185,7 +185,7 @@
# That's it! In just one line of code, we have successfully created the continuous convolutional filter. By default, the `pina.model.FeedForward` neural network is initialized, which can be further customized according to your needs.
-#
+#
# Additionally, if the mesh does not change during training, we can set the `optimize` flag to `True` to leverage optimizations for efficiently finding the points to convolve. This feature helps in improving the performance by reducing redundant calculations when the mesh remains constant.
# In[4]:
@@ -244,10 +244,10 @@ def forward(self, x):
)
-# Notice that we pass the **class** of the model and not an already built object! This is important because the `ContinuousConv` filter will automatically instantiate the model class when needed during training.
-#
+# Notice that we pass the **class** of the model and not an already built object! This is important because the `ContinuousConv` filter will automatically instantiate the model class when needed during training.
+#
# ## Building a MNIST Classifier
-#
+#
# Let's see how we can build a MNIST classifier using a continuous convolutional filter. We will use the MNIST dataset from PyTorch. In order to keep small training times we use only 6000 samples for training and 1000 samples for testing.
# In[7]:
@@ -276,7 +276,7 @@ def forward(self, x):
# Now, let's proceed to build a simple classifier for the MNIST dataset. The MNIST dataset consists of vectors with the shape `[batch, 1, 28, 28]`, but we can treat them as field functions where each pixel at coordinates $i,j$ corresponds to a point in a $[0, 27] \times [0, 27]$ domain. The pixel values represent the field values.
-#
+#
# To use the continuous convolutional filter, we need to transform the regular tensor into a format compatible with the filter. Here's a function that will help with this transformation:
# In[8]:
@@ -401,9 +401,9 @@ def forward(self, x):
# As we can see we have very good performance for having trained only for 1 epoch! Nevertheless, we are still using structured data... Let's see how we can build an autoencoder for unstructured data now.
-#
+#
# ## Building a Continuous Convolutional Autoencoder
-#
+#
# As a toy problem, we will now build an autoencoder for the function \( f(x, y) = \sin(\pi x) \sin(\pi y) \) on the unit circle domain centered at \( (0.5, 0.5) \). We will also explore the ability to up-sample the results (once trained) without needing to retrain the model. To begin, we'll generate the input data for the function. First, we will use a mesh of 100 points and visualize the input function. Here’s how to proceed:
# In[12]:
@@ -451,7 +451,7 @@ def circle_grid(N=100):
# Now, let's create a simple autoencoder using the continuous convolutional filter. Since the data is inherently unstructured, a standard convolutional filter may not be effective without some form of projection or interpolation. We'll begin by building an `Encoder` and `Decoder` class, and then combine them into a unified `Autoencoder` class.
-#
+#
# In[13]:
@@ -608,9 +608,9 @@ def l2_error(input_, target):
# The $l_2$ error is approximately $4\%$, which is quite low considering that we only use **one** convolutional layer and a simple feedforward network to reduce the dimension. Now, let's explore some of the unique features of the filter.
-#
+#
# ### Upsampling with the Filter
-#
+#
# Suppose we have a hidden representation and we want to upsample it on a different grid with more points. Let's see how we can achieve that:
# In[18]:
@@ -656,15 +656,15 @@ def l2_error(input_, target):
# ## What's Next?
-#
+#
# Congratulations on completing the tutorial on using the Continuous Convolutional Filter in **PINA**! Now that you have the basics, there are several exciting directions you can explore:
-#
+#
# 1. **Train using Physics-Informed strategies**: Leverage physics-based knowledge to improve model performance for solving real-world problems.
-#
+#
# 2. **Use the filter to build an unstructured convolutional autoencoder**: Explore reduced-order modeling by implementing unstructured convolutional autoencoders.
-#
+#
# 3. **Experiment with upsampling at different resolutions**: Try encoding or upsampling on different grids to see how the model generalizes across multiple resolutions.
-#
+#
# 4. **...and many more!**: There are endless possibilities, from improving model architecture to testing with more complex datasets.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial5/tutorial.py b/tutorials/tutorial5/tutorial.py
index 4fb990a8d..57acbc989 100644
--- a/tutorials/tutorial5/tutorial.py
+++ b/tutorials/tutorial5/tutorial.py
@@ -2,13 +2,13 @@
# coding: utf-8
# # Tutorial: Modeling 2D Darcy Flow with the Fourier Neural Operator
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial5/tutorial.ipynb)
-#
+#
# In this tutorial, we are going to solve the **Darcy flow problem** in two dimensions, as presented in the paper [*Fourier Neural Operator for Parametric Partial Differential Equations*](https://openreview.net/pdf?id=c8P9NQVtmnO).
-#
+#
# We begin by importing the necessary modules for the tutorial:
-#
+#
# In[ ]:
@@ -22,9 +22,11 @@
IN_COLAB = False
if IN_COLAB:
get_ipython().system('pip install "pina-mathlab[tutorial]"')
- get_ipython().system('pip install scipy')
+ get_ipython().system("pip install scipy")
# get the data
- get_ipython().system('wget https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial5/Data_Darcy.mat')
+ get_ipython().system(
+ "wget https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial5/Data_Darcy.mat"
+ )
import torch
import matplotlib.pyplot as plt
@@ -40,15 +42,15 @@
# ## Data Generation
-#
+#
# We will focus on solving a specific PDE: the **Darcy Flow** equation. This is a second-order elliptic PDE given by:
-#
+#
# $$
# -\nabla\cdot(k(x, y)\nabla u(x, y)) = f(x, y), \quad (x, y) \in D.
# $$
-#
+#
# Here, $u$ represents the flow pressure, $k$ is the permeability field, and $f$ is the forcing function. The Darcy flow equation can be used to model various systems, including flow through porous media, elasticity in materials, and heat conduction.
-#
+#
# In this tutorial, the domain $D$ is defined as a 2D unit square with Dirichlet boundary conditions. The dataset used is taken from the authors' original implementation in the referenced paper.
# In[2]:
@@ -92,7 +94,7 @@
# ## Solving the Problem with a Feedforward Neural Network
-#
+#
# We begin by solving the Darcy flow problem using a standard Feedforward Neural Network (FNN). Since we are approaching this task with supervised learning, we will use the `SupervisedSolver` provided by **PINA** to train the model.
# In[ ]:
@@ -146,7 +148,7 @@
# ## Solving the Problem with a Fourier Neural Operator
-#
+#
# We will now solve the Darcy flow problem using a Fourier Neural Operator (FNO). Since we are learning a mapping between functions—i.e., an operator—this approach is more suitable and often yields better performance, as we will see.
# In[ ]:
@@ -183,7 +185,7 @@
# We can clearly observe that the final loss is significantly lower when using the FNO. Let's now evaluate its performance on the test set.
-#
+#
# Note that the number of trainable parameters in the FNO is considerably higher compared to a `FeedForward` network. Therefore, we recommend using a GPU or TPU to accelerate training, especially when working with large datasets.
# In[11]:
@@ -208,13 +210,13 @@
# As we can see, the loss is significantly lower with the Fourier Neural Operator!
# ## What's Next?
-#
+#
# Congratulations on completing the tutorial on solving the Darcy flow problem using **PINA**! There are many potential next steps you can explore:
-#
+#
# 1. **Train the network longer or with different hyperparameters**: Experiment with different configurations of the neural network. You can try varying the number of layers, activation functions, or learning rates to improve accuracy.
-#
+#
# 2. **Solve more complex problems**: The Darcy flow problem is just the beginning! Try solving other complex problems from the field of parametric PDEs. The original paper and **PINA** documentation offer many more examples to explore.
-#
+#
# 3. **...and many more!**: There are countless directions to further explore. For instance, you could try to add physics informed learning!
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial6/tutorial.py b/tutorials/tutorial6/tutorial.py
index 869fd3a77..0d781ba55 100644
--- a/tutorials/tutorial6/tutorial.py
+++ b/tutorials/tutorial6/tutorial.py
@@ -39,7 +39,6 @@
BaseDomain,
)
-
# ## Built-in Geometries
# We start with PINA’s built-in geometries. In particular, we define a Cartesian domain, an ellipsoid domain, and a simplex domain, all in two dimensions. Extending these constructions to higher dimensions follows the same principles.
diff --git a/tutorials/tutorial7/tutorial.py b/tutorials/tutorial7/tutorial.py
index bf5b55d9b..2e6f772c9 100644
--- a/tutorials/tutorial7/tutorial.py
+++ b/tutorials/tutorial7/tutorial.py
@@ -2,15 +2,15 @@
# coding: utf-8
# # Tutorial: Inverse Problem Solving with Physics-Informed Neural Network
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial7/tutorial.ipynb)
-#
+#
# ## Introduction to the Inverse Problem
-#
+#
# This tutorial demonstrates how to solve an inverse Poisson problem using Physics-Informed Neural Networks (PINNs).
-#
+#
# The problem is defined as a Poisson equation with homogeneous boundary conditions:
-#
+#
# \begin{equation}
# \begin{cases}
# \Delta u = e^{-2(x - \mu_1)^2 - 2(y - \mu_2)^2} \quad \text{in } \Omega, \\
@@ -18,18 +18,18 @@
# u(\mu_1, \mu_2) = \text{data}
# \end{cases}
# \end{equation}
-#
+#
# Here, $\Omega$ is the square domain $[-2, 2] \times [-2, 2]$, and $\partial \Omega = \Gamma_1 \cup \Gamma_2 \cup \Gamma_3 \cup \Gamma_4$ represents the union of its boundaries.
-#
+#
# This type of setup defines an *inverse problem*, which has two primary objectives:
-#
+#
# - **Find the solution** $u$ that satisfies the Poisson equation,
# - **Identify the unknown parameters** $(\mu_1, \mu_2)$ that best fit the given data (as described by the third equation in the system).
-#
+#
# To tackle both objectives, we will define an `InverseProblem` using **PINA**.
-#
+#
# Let's begin with the necessary imports:
-#
+#
# In[1]:
@@ -45,8 +45,12 @@
get_ipython().system('pip install "pina-mathlab[tutorial]"')
# get the data
get_ipython().system('mkdir "data"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial7/data/pinn_solution_0.5_0.5" -O "data/pinn_solution_0.5_0.5"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial7/data/pts_0.5_0.5" -O "data/pts_0.5_0.5"')
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial7/data/pinn_solution_0.5_0.5" -O "data/pinn_solution_0.5_0.5"'
+ )
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial7/data/pts_0.5_0.5" -O "data/pts_0.5_0.5"'
+ )
import matplotlib.pyplot as plt
import torch
@@ -68,14 +72,14 @@
seed_everything(883)
-# Next, we import the pre-saved data corresponding to the true parameter values $(\mu_1, \mu_2) = (0.5, 0.5)$.
+# Next, we import the pre-saved data corresponding to the true parameter values $(\mu_1, \mu_2) = (0.5, 0.5)$.
# These values represent the *optimal parameters* that we aim to recover through neural network training.
-#
+#
# In particular, we load:
-#
+#
# - `input` points — the spatial coordinates where observations are available,
# - `target` points — the corresponding $u$ values (i.e., the solution evaluated at the `input` points).
-#
+#
# This data will be used to guide the inverse problem and supervise the network’s prediction of the unknown parameters.
# In[2]:
@@ -88,10 +92,10 @@
# Next, let's visualize the data:
-#
+#
# - We'll plot the data points, i.e., the spatial coordinates where measurements are available.
# - We'll also display the reference solution corresponding to $(\mu_1, \mu_2) = (0.5, 0.5)$.
-#
+#
# This serves as the ground truth or expected output that our neural network should learn to approximate through training.
# In[3]:
@@ -107,10 +111,10 @@
# ## Inverse Problem Definition in PINA
-#
-# Next, we initialize the Poisson problem, which inherits from the `SpatialProblem` and `InverseProblem` classes.
+#
+# Next, we initialize the Poisson problem, which inherits from the `SpatialProblem` and `InverseProblem` classes.
# In this step, we need to define all the variables and specify the domain in which our unknown parameters $(\mu_1, \mu_2)$ reside.
-#
+#
# Note that the Laplace equation also takes these unknown parameters as inputs. These parameters will be treated as variables that the neural network will optimize during the training process, enabling it to learn the optimal values for $(\mu_1, \mu_2)$.
# In[4]:
@@ -179,11 +183,11 @@ class Poisson(SpatialProblem, InverseProblem):
problem.discretise_domain(1000, "random", domains="boundary")
-# Here, we define a simple callback for the trainer. This callback is used to save the parameters predicted by the neural network during training.
+# Here, we define a simple callback for the trainer. This callback is used to save the parameters predicted by the neural network during training.
# The parameters are saved every 100 epochs as `torch` tensors in a specified directory (in our case, `tutorial_logs`).
-#
+#
# The goal of this setup is to read the saved parameters after training and visualize their trend across the epochs. This allows us to monitor how the predicted parameters evolve throughout the training process.
-#
+#
# In[7]:
@@ -256,13 +260,13 @@ def on_train_epoch_end(self, trainer, __):
# ## What's Next?
-#
+#
# We have covered the basic usage of PINNs for inverse problem modeling. Here are some possible directions for further exploration:
-#
+#
# 1. **Experiment with different Physics-Informed strategies**: Explore variations in PINN training techniques to improve performance or tackle different types of problems.
-#
+#
# 2. **Apply to more complex problems**: Scale the approach to higher-dimensional or time-dependent inverse problems.
-#
+#
# 3. **...and many more!**: The possibilities are endless, from integrating additional physical constraints to testing on real-world datasets.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial8/tutorial.ipynb b/tutorials/tutorial8/tutorial.ipynb
index 015d3b288..1d2f9dc3e 100644
--- a/tutorials/tutorial8/tutorial.ipynb
+++ b/tutorials/tutorial8/tutorial.ipynb
@@ -196,7 +196,7 @@
"# fit the pod basis\n",
"trainer.data_module.setup(\"fit\") # set up the dataset\n",
"train_data = trainer.data_module.train_datasets[\"data\"].get_all_data()\n",
- "x_train = train_data.target # extract data for training\n",
+ "x_train = train_data.target # extract data for training\n",
"pod_nn.fit_pod(x=x_train)\n",
"\n",
"# now train\n",
diff --git a/tutorials/tutorial8/tutorial.py b/tutorials/tutorial8/tutorial.py
index f20157d67..659a52cde 100644
--- a/tutorials/tutorial8/tutorial.py
+++ b/tutorials/tutorial8/tutorial.py
@@ -2,13 +2,13 @@
# coding: utf-8
# # Tutorial: Reduced Order Modeling with POD-RBF and POD-NN Approaches for Fluid Dynamics
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial8/tutorial.ipynb)
# The goal of this tutorial is to demonstrate how to use the **PINA** library to apply a reduced-order modeling technique, as outlined in [1]. These methods share several similarities with machine learning approaches, as they focus on predicting the solution to differential equations, often parametric PDEs, in real-time.
-#
+#
# In particular, we will utilize **Proper Orthogonal Decomposition** (POD) in combination with two different regression techniques: **Radial Basis Function Interpolation** (POD-RBF) and **Neural Networks**(POD-NN) [2]. This process involves reducing the dimensionality of the parametric solution manifold through POD and then approximating it in the reduced space using a regression model (either a neural network or an RBF interpolation). In this example, we'll use a simple multilayer perceptron (MLP) as the regression model, but various architectures can be easily substituted.
-#
+#
# Let's start with the necessary imports.
# In[1]:
@@ -42,9 +42,9 @@
# We utilize the [Smithers](https://github.com/mathLab/Smithers) library to gather the parametric snapshots. Specifically, we use the `NavierStokesDataset` class, which contains a collection of parametric solutions to the Navier-Stokes equations in a 2D L-shaped domain. The parameter in this case is the inflow velocity.
-#
+#
# The dataset comprises 500 snapshots of the velocity fields (along the $x$, $y$ axes, and the magnitude), as well as the pressure fields, along with their corresponding parameter values.
-#
+#
# To visually inspect the snapshots, let's also plot the data points alongside the reference solution. This reference solution represents the expected output of our model.
# In[2]:
@@ -61,7 +61,7 @@
# The *snapshots*—i.e., the numerical solutions computed for several parameters—and the corresponding parameters are the only data we need to train the model, enabling us to predict the solution for any new test parameter. To properly validate the accuracy, we will split the 500 snapshots into the training dataset (90% of the original data) and the testing dataset (the remaining 10%) inside the `Trainer`.
-#
+#
# It is now time to define the problem!
# In[3]:
@@ -73,7 +73,7 @@
# We can then build a `POD-NN` model (using an MLP architecture as approximation) and compare it with a `POD-RBF` model (using a Radial Basis Function interpolation as approximation).
-#
+#
# ## POD-NN reduced order model
# Let's build the `PODNN` class
@@ -163,7 +163,7 @@ def fit_pod(self, x):
# ## POD-RBF Reduced Order Model
-#
+#
# Next, we define the model we want to use, incorporating the `PODBlock` and `RBFBlock` objects.
# In[8]:
@@ -210,9 +210,9 @@ def fit(self, p, x):
# ## POD-RBF vs POD-NN
-#
+#
# We can compare the solutions predicted by the `POD-RBF` and the `POD-NN` models with the original reference solution. By plotting these predicted solutions against the true solution, we can observe how each model performs.
-#
+#
# ### Observations:
# - **POD-RBF**: The solution predicted by the `POD-RBF` model typically offers a smooth approximation for the parametric solution, as RBF interpolation is well-suited for capturing smooth variations.
# - **POD-NN**: The `POD-NN` model, while more flexible due to the neural network architecture, may show some discrepancies—especially for low velocities or in regions where the training data is sparse. However, with longer training times and adjustments in the network architecture, we can improve the predictions.
@@ -274,21 +274,21 @@ def fit(self, p, x):
# ## What's Next?
-#
+#
# Congratulations on completing this tutorial using **PINA** to apply reduced order modeling techniques with **POD-RBF** and **POD-NN**! There are several directions you can explore next:
-#
+#
# 1. **Extend to More Complex Problems**: Try using more complex parametric domains or PDEs. For example, you can explore Navier-Stokes equations in 3D or more complex boundary conditions.
-#
+#
# 2. **Combine POD with Deep Learning Techniques**: Investigate hybrid methods, such as combining **POD-NN** with convolutional layers or recurrent layers, to handle time-dependent problems or more complex spatial dependencies.
-#
+#
# 3. **Evaluate Performance on Larger Datasets**: Work with larger datasets to assess how well these methods scale. You may want to test on datasets from simulations or real-world problems.
-#
+#
# 4. **Hybrid Models with Physics Informed Networks (PINN)**: Integrate **POD** models with PINN frameworks to include physics-based regularization in your model and improve predictions for more complex scenarios, such as turbulent fluid flow.
-#
+#
# 5. **...and many more!**: The potential applications of reduced order models are vast, ranging from material science simulations to real-time predictions in engineering applications.
-#
+#
# For more information and advanced tutorials, refer to the [PINA Documentation](https://mathlab.github.io/PINA/).
-#
+#
# ### References
-# 1. Rozza G., Stabile G., Ballarin F. (2022). Advanced Reduced Order Methods and Applications in Computational Fluid Dynamics, Society for Industrial and Applied Mathematics.
+# 1. Rozza G., Stabile G., Ballarin F. (2022). Advanced Reduced Order Methods and Applications in Computational Fluid Dynamics, Society for Industrial and Applied Mathematics.
# 2. Hesthaven, J. S., & Ubbiali, S. (2018). Non-intrusive reduced order modeling of nonlinear problems using neural networks. Journal of Computational Physics, 363, 55-78.
diff --git a/tutorials/tutorial9/tutorial.ipynb b/tutorials/tutorial9/tutorial.ipynb
index 845d649ff..a23ed1abb 100644
--- a/tutorials/tutorial9/tutorial.ipynb
+++ b/tutorials/tutorial9/tutorial.ipynb
@@ -94,7 +94,9 @@
" return -6.0 * pi**2 * torch.sin(3 * pi * x) * torch.cos(pi * x)\n",
"\n",
"\n",
- "helmholtz_equation = HelmholtzEquation(k=10 * torch.pi**2, forcing_term=forcing_term)\n",
+ "helmholtz_equation = HelmholtzEquation(\n",
+ " k=10 * torch.pi**2, forcing_term=forcing_term\n",
+ ")\n",
"\n",
"\n",
"class Helmholtz(SpatialProblem):\n",
diff --git a/tutorials/tutorial9/tutorial.py b/tutorials/tutorial9/tutorial.py
index 4f5809826..b7f2a997c 100644
--- a/tutorials/tutorial9/tutorial.py
+++ b/tutorials/tutorial9/tutorial.py
@@ -2,14 +2,14 @@
# coding: utf-8
# # Tutorial: Applying Periodic Boundary Conditions in PINNs to solve the Helmholtz Problem
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial9/tutorial.ipynb)
-#
-# This tutorial demonstrates how to solve a one-dimensional Helmholtz equation with periodic boundary conditions (PBC) using Physics-Informed Neural Networks (PINNs).
+#
+# This tutorial demonstrates how to solve a one-dimensional Helmholtz equation with periodic boundary conditions (PBC) using Physics-Informed Neural Networks (PINNs).
# We will use standard PINN training, augmented with a periodic input expansion as introduced in [*An Expert’s Guide to Training Physics-Informed Neural Networks*](https://arxiv.org/abs/2308.08468).
-#
+#
# Let's start with some useful imports:
-#
+#
# In[ ]:
@@ -41,33 +41,33 @@
# ## Problem Definition
-#
+#
# The one-dimensional Helmholtz problem is mathematically expressed as:
-#
+#
# $$
# \begin{cases}
# \frac{d^2}{dx^2}u(x) - \lambda u(x) - f(x) &= 0 \quad \text{for } x \in (0, 2) \\
# u^{(m)}(x = 0) - u^{(m)}(x = 2) &= 0 \quad \text{for } m \in \{0, 1, \dots\}
# \end{cases}
# $$
-#
-# In this case, we seek a solution that is $C^{\infty}$ (infinitely differentiable) and periodic with period 2, over the infinite domain $x \in (-\infty, \infty)$.
-#
+#
+# In this case, we seek a solution that is $C^{\infty}$ (infinitely differentiable) and periodic with period 2, over the infinite domain $x \in (-\infty, \infty)$.
+#
# A classical PINN approach would require enforcing periodic boundary conditions (PBC) for all derivatives—an infinite set of constraints—which is clearly infeasible.
-#
+#
# To address this, we adopt a strategy known as *coordinate augmentation*. In this approach, we apply a coordinate transformation $v(x)$ such that the transformed inputs naturally satisfy the periodicity condition:
-#
+#
# $$
# u^{(m)}(x = 0) - u^{(m)}(x = 2) = 0 \quad \text{for } m \in \{0, 1, \dots\}
# $$
-#
+#
# For demonstration purposes, we choose the specific parameters:
-#
+#
# - $\lambda = -10\pi^2$
# - $f(x) = -6\pi^2 \sin(3\pi x) \cos(\pi x)$
-#
+#
# These yield an analytical solution:
-#
+#
# $$
# u(x) = \sin(\pi x) \cos(3\pi x)
# $$
@@ -105,39 +105,39 @@ def solution(self, pts):
# As usual, the Helmholtz problem is implemented in **PINA** as a class. The governing equations are defined as `conditions`, which must be satisfied within their respective domains. The `solution` represents the exact analytical solution, which will be used to evaluate the accuracy of the predicted solution.
-#
-# For selecting collocation points, we use Latin Hypercube Sampling (LHS), a common strategy for efficient space-filling in high-dimensional domains
-#
+#
+# For selecting collocation points, we use Latin Hypercube Sampling (LHS), a common strategy for efficient space-filling in high-dimensional domains
+#
# ## Solving the Problem with a Periodic Network
-#
-# Any $\mathcal{C}^{\infty}$ periodic function $u : \mathbb{R} \rightarrow \mathbb{R}$ with period $L \in \mathbb{N}$
+#
+# Any $\mathcal{C}^{\infty}$ periodic function $u : \mathbb{R} \rightarrow \mathbb{R}$ with period $L \in \mathbb{N}$
# can be constructed by composing an arbitrary smooth function $f : \mathbb{R}^n \rightarrow \mathbb{R}$ with a smooth, periodic mapping$v : \mathbb{R} \rightarrow \mathbb{R}^n$ of the same period $L$. That is,
-#
+#
# $$
# u(x) = f(v(x)).
# $$
-#
-# This formulation is general and can be extended to arbitrary dimensions.
+#
+# This formulation is general and can be extended to arbitrary dimensions.
# For more details, see [*A Method for Representing Periodic Functions and Enforcing Exactly Periodic Boundary Conditions with Deep Neural Networks*](https://arxiv.org/pdf/2007.07442).
-#
+#
# In our specific case, we define the periodic embedding as:
-#
+#
# $$
# v(x) = \left[1, \cos\left(\frac{2\pi}{L} x\right), \sin\left(\frac{2\pi}{L} x\right)\right],
# $$
-#
+#
# which constitutes the coordinate augmentation. The function $f(\cdot)$ is approximated by a neural network $NN_{\theta}(\cdot)$, resulting in the approximate PINN solution:
-#
+#
# $$
# u(x) \approx u_{\theta}(x) = NN_{\theta}(v(x)).
# $$
-#
-# In **PINA**, this is implemented using the `PeriodicBoundaryEmbedding` layer for $v(x)$,
-# paired with any `pina.model` to define the neural network $NN_{\theta}$.
-#
+#
+# In **PINA**, this is implemented using the `PeriodicBoundaryEmbedding` layer for $v(x)$,
+# paired with any `pina.model` to define the neural network $NN_{\theta}$.
+#
# Let’s see how this is put into practice!
-#
-#
+#
+#
# In[3]:
@@ -154,11 +154,11 @@ def solution(self, pts):
# As simple as that!
-#
-# In higher dimensions, you can specify different periods for each coordinate using a dictionary.
-# For example, `periods = {'x': 2, 'y': 3, ...}` indicates a periodicity of 2 in the $x$ direction,
+#
+# In higher dimensions, you can specify different periods for each coordinate using a dictionary.
+# For example, `periods = {'x': 2, 'y': 3, ...}` indicates a periodicity of 2 in the $x$ direction,
# 3 in the $y$ direction, and so on.
-#
+#
# We will now solve the problem using the usual `PINN` and `Trainer` classes. After training, we'll examine the losses using the `MetricTracker` callback from `pina.callback`.
# In[ ]:
@@ -234,15 +234,15 @@ def solution(self, pts):
# It's clear that the network successfully captures the periodicity of the solution, with the error also exhibiting a periodic pattern. Naturally, training for a longer duration or using a more expressive neural network could further improve the results.
# ## What's next?
-#
+#
# Congratulations on completing the one-dimensional Helmholtz tutorial with **PINA**! Here are a few directions you can explore next:
-#
+#
# 1. **Train longer or with different architectures**: Experiment with extended training or modify the network's depth and width to evaluate improvements in accuracy.
-#
+#
# 2. **Apply `PeriodicBoundaryEmbedding` to time-dependent problems**: Explore more complex scenarios such as spatiotemporal PDEs (see the official documentation for examples).
-#
+#
# 3. **Try extra feature training**: Integrate additional physical or domain-specific features to guide the learning process more effectively.
-#
+#
# 4. **...and many more!**: Extend to higher dimensions, test on other PDEs, or even develop custom embeddings tailored to your problem.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
#
#
# Image source: Moya & Lin (2022)
#
-#
+#
# In our setting:
# - The **branch network** receives the initial condition of each trajectory, with input shape `[B, Nx]` — where `B` is the batch size and `Nx` the spatial discretization points of the field at \( t = 0 \).
# - The **trunk network** takes input of shape `[B, 1]`, corresponding to the location at which we evaluate the solution (in this 1D case, the spatial coordinate).
-#
+#
# Together, these networks learn the mapping from the initial field to the solution at a later time.
-#
+#
# We now define and train the model for the advection problem.
# In[4]:
@@ -181,9 +189,9 @@ def forward(self, x):
# The `TrunkNet` is implemented as a standard `FeedForward` network with a slightly modified `forward` method. In this case, the trunk network simply outputs a tensor filled with the value \(0.5\), repeated for each trajectory — corresponding to evaluating the solution at time \(t = 0.5\).
-#
+#
# The `BranchNet` is also a `FeedForward` network, but its `forward` pass first flattens the input along the last dimension. This produces a vector of length `Nx`, representing the sampled initial condition at the sensor locations.
-#
+#
# With both subnetworks defined, we can now instantiate the DeepONet model using the `DeepONet` class from `pina.model`.
# In[6]:
@@ -215,7 +223,7 @@ def forward(self, x):
# The aggregation and reduction functions combine the outputs of the branch and trunk networks. In this example, their outputs are multiplied element-wise, and no reduction is applied — meaning the final output has the same dimensionality as each network’s output.
-#
+#
# We train the model using a `SupervisedSolver` with an `MSE` loss. Below, we first define the solver and then the trainer used to run the optimization.
# In[ ]:
@@ -269,7 +277,7 @@ def forward(self, x):
plt.show()
-# As we can see, they are barely indistinguishable. To better understand the difference, we now plot the residuals, i.e. the difference of the exact solution and the predicted one.
+# As we can see, they are barely indistinguishable. To better understand the difference, we now plot the residuals, i.e. the difference of the exact solution and the predicted one.
# In[10]:
@@ -288,17 +296,17 @@ def forward(self, x):
# ## What's Next?
-#
+#
# We have seen a simple example of using `DeepONet` to learn the advection operator. This only scratches the surface of what neural operators can do. Here are some suggested directions to continue your exploration:
-#
+#
# 1. **Train on more complex PDEs**: Extend beyond the advection equation to more challenging operators, such as diffusion or nonlinear conservation laws.
-#
+#
# 2. **Increase training scope**: Experiment with larger datasets, deeper networks, and longer training schedules to unlock the full potential of neural operator learning.
-#
+#
# 3. **Generalize to the full advection operator**: Train the model to learn the general operator $\mathcal{G}_t: u_0(x) \mapsto u(x,t) = u_0(x - t)$ so the network predicts solutions for arbitrary times, not just a single fixed horizon.
-#
+#
# 4. **Investigate architectural variations**: Compare different operator learning architectures (e.g., Fourier Neural Operators, Physics-Informed DeepONets) to see how they perform on similar problems.
-#
+#
# 5. **...and much more!**: From adding noise robustness to testing on real scientific datasets, the space of possibilities is wide open.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial3/tutorial.py b/tutorials/tutorial3/tutorial.py
index d01534a79..5f7d7c03b 100644
--- a/tutorials/tutorial3/tutorial.py
+++ b/tutorials/tutorial3/tutorial.py
@@ -2,11 +2,11 @@
# coding: utf-8
# # Tutorial: Applying Hard Constraints in PINNs to solve the Wave Problem
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial3/tutorial.ipynb)
-#
+#
# In this tutorial, we will present how to solve the wave equation using **hard constraint Physics-Informed Neural Networks (PINNs)**. To achieve this, we will build a custom `torch` model and pass it to the **PINN solver**.
-#
+#
# First of all, some useful imports.
# In[ ]:
@@ -37,10 +37,10 @@
warnings.filterwarnings("ignore")
-# ## The problem definition
-#
+# ## The problem definition
+#
# The problem is described by the following system of partial differential equations (PDEs):
-#
+#
# \begin{equation}
# \begin{cases}
# \Delta u(x,y,t) = \frac{\partial^2}{\partial t^2} u(x,y,t) \quad \text{in } D, \\\\
@@ -48,9 +48,9 @@
# u(x, y, t) = 0 \quad \text{on } \Gamma_1 \cup \Gamma_2 \cup \Gamma_3 \cup \Gamma_4,
# \end{cases}
# \end{equation}
-#
+#
# Where:
-#
+#
# - $D$ is a square domain $[0, 1]^2$.
# - $\Gamma_i$, where $i = 1, \dots, 4$, are the boundaries of the square where Dirichlet conditions are applied.
# - The velocity in the standard wave equation is fixed to $1$.
@@ -101,13 +101,13 @@ def solution(self, pts):
# ## Hard Constraint Model
-#
+#
# Once the problem is defined, a **torch** model is needed to solve the PINN. While **PINA** provides several pre-implemented models, users have the option to build their own custom model using **torch**. The hard constraint we impose is on the boundary of the spatial domain. Specifically, the solution is written as:
-#
+#
# $$ u_{\rm{pinn}} = xy(1-x)(1-y)\cdot NN(x, y, t), $$
-#
+#
# where $NN$ represents the neural network output. This neural network takes the spatial coordinates $x$, $y$, and time $t$ as input and provides the unknown field $u$. By construction, the solution is zero at the boundaries.
-#
+#
# The residuals of the equations are evaluated at several sampling points (which the user can manipulate using the `discretise_domain` method). The loss function minimized by the neural network is the sum of the residuals.
# In[3]:
@@ -233,13 +233,13 @@ def plot_solution(solver, time):
# The results are not ideal, and we can clearly see that as time progresses, the solution deteriorates. Can we do better?
-#
+#
# One valid approach is to impose the initial condition as a hard constraint as well. Specifically, we modify the solution to:
-#
+#
# $$
# u_{\rm{pinn}} = xy(1-x)(1-y) \cdot NN(x, y, t) \cdot t + \cos(\sqrt{2}\pi t)\sin(\pi x)\sin(\pi y),
# $$
-#
+#
# Now, let us start by building the neural network.
# In[8]:
@@ -319,19 +319,19 @@ def forward(self, x):
# We can now see that the results are much better! This improvement is due to the fact that, previously, the network was not correctly learning the initial condition, which led to a poor solution as time evolved. By imposing the initial condition as a hard constraint, the network is now able to correctly solve the problem.
# ## What's Next?
-#
+#
# Congratulations on completing the two-dimensional Wave tutorial of **PINA**! Now that you’ve got the basics down, there are several directions you can explore:
-#
+#
# 1. **Train the Network for Longer**: Train the network for a longer duration or experiment with different layer sizes to assess the final accuracy.
-#
+#
# 2. **Propose New Types of Hard Constraints in Time**: Experiment with new time-dependent hard constraints, for example:
-#
+#
# $$
# u_{\rm{pinn}} = xy(1-x)(1-y)\cdot NN(x, y, t)(1-\exp(-t)) + \cos(\sqrt{2}\pi t)\sin(\pi x)\sin(\pi y)
# $$
-#
+#
# 3. **Exploit Extrafeature Training**: Apply extrafeature training techniques to improve models from 1 and 2.
-#
+#
# 4. **...and many more!**: The possibilities are endless! Keep experimenting and pushing the boundaries.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial4/tutorial.py b/tutorials/tutorial4/tutorial.py
index ae0004ddf..67680d591 100644
--- a/tutorials/tutorial4/tutorial.py
+++ b/tutorials/tutorial4/tutorial.py
@@ -5,7 +5,7 @@
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial4/tutorial.ipynb)
# In this tutorial, we will show how to use the Continuous Convolutional Filter, and how to build common Deep Learning architectures with it. The implementation of the filter follows the original work [*A Continuous Convolutional Trainable Filter for Modelling Unstructured Data*](https://arxiv.org/abs/2210.13416).
-#
+#
# First of all we import the modules needed for the tutorial:
# In[ ]:
@@ -37,72 +37,72 @@
# ## Tutorial Structure
-#
+#
# The tutorial is structured as follows:
-#
-# - [🔹 Continuous Filter Background](#continuous-filter-background):
+#
+# - [🔹 Continuous Filter Background](#continuous-filter-background):
# Understand how the convolutional filter works and how to use it.
-#
-# - [🔹 Building a MNIST Classifier](#building-a-mnist-classifier):
+#
+# - [🔹 Building a MNIST Classifier](#building-a-mnist-classifier):
# Learn how to build a simple classifier using the MNIST dataset, and how to combine a continuous convolutional layer with a feedforward neural network.
-#
-# - [🔹 Building a Continuous Convolutional Autoencoder](#building-a-continuous-convolutional-autoencoder):
+#
+# - [🔹 Building a Continuous Convolutional Autoencoder](#building-a-continuous-convolutional-autoencoder):
# Explore how to use the continuous filter to work with unstructured data for autoencoding and up-sampling.
-#
+#
# ## Continuous Filter Background
-#
+#
# As reported by the authors in the original paper, in contrast to discrete convolution, **continuous convolution** is mathematically defined as:
-#
+#
# $$
# \mathcal{I}_{\rm{out}}(\mathbf{x}) = \int_{\mathcal{X}} \mathcal{I}(\mathbf{x} + \mathbf{\tau}) \cdot \mathcal{K}(\mathbf{\tau}) d\mathbf{\tau},
# $$
-#
+#
# where:
# - $\mathcal{K} : \mathcal{X} \rightarrow \mathbb{R}$ is the **continuous filter** function,
# - $\mathcal{I} : \Omega \subset \mathbb{R}^N \rightarrow \mathbb{R}$ is the input function.
-#
+#
# The **continuous filter function** is approximated using a **FeedForward Neural Network**, which is **trainable** during the training phase. The way in which the integral is approximated can vary. In the **PINA** framework, we approximate it using a simple sum, as suggested by the authors. Thus, given the points $\{\mathbf{x}_i\}_{i=1}^{n}$ in $\mathbb{R}^N$ mapped onto the filter domain $\mathcal{X}$, we approximate the equation as:
-#
+#
# $$
# \mathcal{I}_{\rm{out}}(\mathbf{\tilde{x}}_i) = \sum_{{\mathbf{x}_i}\in\mathcal{X}} \mathcal{I}(\mathbf{x}_i + \mathbf{\tau}) \cdot \mathcal{K}(\mathbf{x}_i),
# $$
-#
+#
# where $\mathbf{\tau} \in \mathcal{S}$, with $\mathcal{S}$ being the set of available strides, represents the current stride position of the filter. The $\mathbf{\tilde{x}}_i$ points are obtained by taking the **centroid** of the filter position mapped onto the domain $\Omega$.
-#
+#
# ### Working with the Continuous Filter
-#
+#
# From the above definition, what is needed is:
# 1. A **domain** and a **function** defined on that domain (the input),
# 2. A **stride**, corresponding to the positions where the filter needs to be applied (this is the `stride` variable in `ContinuousConv`),
# 3. The **filter's rectangular domain**, which corresponds to the `filter_dim` variable in `ContinuousConv`.
-#
+#
# ### Input Function
-#
+#
# The input function for the continuous filter is defined as a tensor of shape:
-#
+#
# $$[B \times N_{\text{in}} \times N \times D]$$
-#
+#
# where:
# - $B$ is the **batch size**,
# - $N_{\text{in}}$ is the number of input fields,
# - $N$ is the number of points in the mesh,
-# - $D$ is the dimension of the problem.
-#
+# - $D$ is the dimension of the problem.
+#
# In particular:
# - $D$ represents the **number of spatial variables** + 1. The last column must contain the field value. For example, for 2D problems, $D=3$ and the tensor will look like `[first coordinate, second coordinate, field value]`.
# - $N_{\text{in}}$ represents the number of vectorial functions presented. For example, a vectorial function $f = [f_1, f_2]$ will have $N_{\text{in}}=2$.
-#
+#
# #### Example: Input Function for a Vectorial Field
-#
+#
# Let’s see an example to clarify the idea. Suppose we wish to create the function:
-#
+#
# $$
# f(x, y) = [\sin(\pi x) \sin(\pi y), -\sin(\pi x) \sin(\pi y)] \quad (x,y)\in[0,1]\times[0,1]
# $$
-#
+#
# We can do this with a **batch size** equal to 1. This function consists of two components (vectorial field), so $N_{\text{in}}=2$. For each $(x,y)$ pair in the domain $[0,1] \times [0,1]$, we will compute the corresponding field values:
-#
+#
# 1. $\sin(\pi x) \sin(\pi y)$
# 2. $-\sin(\pi x) \sin(\pi y)$
@@ -139,9 +139,9 @@
# ### Stride
-#
+#
# The **stride** is passed as a dictionary `stride` that dictates where the filter should move. Here's an example for the domain $[0,1] \times [0,5]$:
-#
+#
# ```python
# # stride definition
# stride = {"domain": [1, 5],
@@ -155,9 +155,9 @@
# 2. `start`: The starting position of the filter's centroid. In this example, the filter starts at the position $(0, 0)$.
# 3. `jump`: The steps or jumps of the filter’s centroid to the next position. In this example, the filter moves by $(0.1, 0.3)$ along the x and y axes respectively.
# 4. `direction`: The directions of the jumps for each coordinate. A value of 1 indicates the filter moves right, 0 means no movement, and -1 indicates the filter moves left with respect to its current position.
-#
+#
# ### Filter definition
-#
+#
# Now that we have defined the stride, we can move on to construct the continuous filter.
# Let’s assume we want the output to contain only one field, and we will set the filter dimension to be $[0.1, 0.1]$.
@@ -185,7 +185,7 @@
# That's it! In just one line of code, we have successfully created the continuous convolutional filter. By default, the `pina.model.FeedForward` neural network is initialized, which can be further customized according to your needs.
-#
+#
# Additionally, if the mesh does not change during training, we can set the `optimize` flag to `True` to leverage optimizations for efficiently finding the points to convolve. This feature helps in improving the performance by reducing redundant calculations when the mesh remains constant.
# In[4]:
@@ -244,10 +244,10 @@ def forward(self, x):
)
-# Notice that we pass the **class** of the model and not an already built object! This is important because the `ContinuousConv` filter will automatically instantiate the model class when needed during training.
-#
+# Notice that we pass the **class** of the model and not an already built object! This is important because the `ContinuousConv` filter will automatically instantiate the model class when needed during training.
+#
# ## Building a MNIST Classifier
-#
+#
# Let's see how we can build a MNIST classifier using a continuous convolutional filter. We will use the MNIST dataset from PyTorch. In order to keep small training times we use only 6000 samples for training and 1000 samples for testing.
# In[7]:
@@ -276,7 +276,7 @@ def forward(self, x):
# Now, let's proceed to build a simple classifier for the MNIST dataset. The MNIST dataset consists of vectors with the shape `[batch, 1, 28, 28]`, but we can treat them as field functions where each pixel at coordinates $i,j$ corresponds to a point in a $[0, 27] \times [0, 27]$ domain. The pixel values represent the field values.
-#
+#
# To use the continuous convolutional filter, we need to transform the regular tensor into a format compatible with the filter. Here's a function that will help with this transformation:
# In[8]:
@@ -401,9 +401,9 @@ def forward(self, x):
# As we can see we have very good performance for having trained only for 1 epoch! Nevertheless, we are still using structured data... Let's see how we can build an autoencoder for unstructured data now.
-#
+#
# ## Building a Continuous Convolutional Autoencoder
-#
+#
# As a toy problem, we will now build an autoencoder for the function \( f(x, y) = \sin(\pi x) \sin(\pi y) \) on the unit circle domain centered at \( (0.5, 0.5) \). We will also explore the ability to up-sample the results (once trained) without needing to retrain the model. To begin, we'll generate the input data for the function. First, we will use a mesh of 100 points and visualize the input function. Here’s how to proceed:
# In[12]:
@@ -451,7 +451,7 @@ def circle_grid(N=100):
# Now, let's create a simple autoencoder using the continuous convolutional filter. Since the data is inherently unstructured, a standard convolutional filter may not be effective without some form of projection or interpolation. We'll begin by building an `Encoder` and `Decoder` class, and then combine them into a unified `Autoencoder` class.
-#
+#
# In[13]:
@@ -608,9 +608,9 @@ def l2_error(input_, target):
# The $l_2$ error is approximately $4\%$, which is quite low considering that we only use **one** convolutional layer and a simple feedforward network to reduce the dimension. Now, let's explore some of the unique features of the filter.
-#
+#
# ### Upsampling with the Filter
-#
+#
# Suppose we have a hidden representation and we want to upsample it on a different grid with more points. Let's see how we can achieve that:
# In[18]:
@@ -656,15 +656,15 @@ def l2_error(input_, target):
# ## What's Next?
-#
+#
# Congratulations on completing the tutorial on using the Continuous Convolutional Filter in **PINA**! Now that you have the basics, there are several exciting directions you can explore:
-#
+#
# 1. **Train using Physics-Informed strategies**: Leverage physics-based knowledge to improve model performance for solving real-world problems.
-#
+#
# 2. **Use the filter to build an unstructured convolutional autoencoder**: Explore reduced-order modeling by implementing unstructured convolutional autoencoders.
-#
+#
# 3. **Experiment with upsampling at different resolutions**: Try encoding or upsampling on different grids to see how the model generalizes across multiple resolutions.
-#
+#
# 4. **...and many more!**: There are endless possibilities, from improving model architecture to testing with more complex datasets.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial5/tutorial.py b/tutorials/tutorial5/tutorial.py
index 4fb990a8d..57acbc989 100644
--- a/tutorials/tutorial5/tutorial.py
+++ b/tutorials/tutorial5/tutorial.py
@@ -2,13 +2,13 @@
# coding: utf-8
# # Tutorial: Modeling 2D Darcy Flow with the Fourier Neural Operator
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial5/tutorial.ipynb)
-#
+#
# In this tutorial, we are going to solve the **Darcy flow problem** in two dimensions, as presented in the paper [*Fourier Neural Operator for Parametric Partial Differential Equations*](https://openreview.net/pdf?id=c8P9NQVtmnO).
-#
+#
# We begin by importing the necessary modules for the tutorial:
-#
+#
# In[ ]:
@@ -22,9 +22,11 @@
IN_COLAB = False
if IN_COLAB:
get_ipython().system('pip install "pina-mathlab[tutorial]"')
- get_ipython().system('pip install scipy')
+ get_ipython().system("pip install scipy")
# get the data
- get_ipython().system('wget https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial5/Data_Darcy.mat')
+ get_ipython().system(
+ "wget https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial5/Data_Darcy.mat"
+ )
import torch
import matplotlib.pyplot as plt
@@ -40,15 +42,15 @@
# ## Data Generation
-#
+#
# We will focus on solving a specific PDE: the **Darcy Flow** equation. This is a second-order elliptic PDE given by:
-#
+#
# $$
# -\nabla\cdot(k(x, y)\nabla u(x, y)) = f(x, y), \quad (x, y) \in D.
# $$
-#
+#
# Here, $u$ represents the flow pressure, $k$ is the permeability field, and $f$ is the forcing function. The Darcy flow equation can be used to model various systems, including flow through porous media, elasticity in materials, and heat conduction.
-#
+#
# In this tutorial, the domain $D$ is defined as a 2D unit square with Dirichlet boundary conditions. The dataset used is taken from the authors' original implementation in the referenced paper.
# In[2]:
@@ -92,7 +94,7 @@
# ## Solving the Problem with a Feedforward Neural Network
-#
+#
# We begin by solving the Darcy flow problem using a standard Feedforward Neural Network (FNN). Since we are approaching this task with supervised learning, we will use the `SupervisedSolver` provided by **PINA** to train the model.
# In[ ]:
@@ -146,7 +148,7 @@
# ## Solving the Problem with a Fourier Neural Operator
-#
+#
# We will now solve the Darcy flow problem using a Fourier Neural Operator (FNO). Since we are learning a mapping between functions—i.e., an operator—this approach is more suitable and often yields better performance, as we will see.
# In[ ]:
@@ -183,7 +185,7 @@
# We can clearly observe that the final loss is significantly lower when using the FNO. Let's now evaluate its performance on the test set.
-#
+#
# Note that the number of trainable parameters in the FNO is considerably higher compared to a `FeedForward` network. Therefore, we recommend using a GPU or TPU to accelerate training, especially when working with large datasets.
# In[11]:
@@ -208,13 +210,13 @@
# As we can see, the loss is significantly lower with the Fourier Neural Operator!
# ## What's Next?
-#
+#
# Congratulations on completing the tutorial on solving the Darcy flow problem using **PINA**! There are many potential next steps you can explore:
-#
+#
# 1. **Train the network longer or with different hyperparameters**: Experiment with different configurations of the neural network. You can try varying the number of layers, activation functions, or learning rates to improve accuracy.
-#
+#
# 2. **Solve more complex problems**: The Darcy flow problem is just the beginning! Try solving other complex problems from the field of parametric PDEs. The original paper and **PINA** documentation offer many more examples to explore.
-#
+#
# 3. **...and many more!**: There are countless directions to further explore. For instance, you could try to add physics informed learning!
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial6/tutorial.py b/tutorials/tutorial6/tutorial.py
index 869fd3a77..0d781ba55 100644
--- a/tutorials/tutorial6/tutorial.py
+++ b/tutorials/tutorial6/tutorial.py
@@ -39,7 +39,6 @@
BaseDomain,
)
-
# ## Built-in Geometries
# We start with PINA’s built-in geometries. In particular, we define a Cartesian domain, an ellipsoid domain, and a simplex domain, all in two dimensions. Extending these constructions to higher dimensions follows the same principles.
diff --git a/tutorials/tutorial7/tutorial.py b/tutorials/tutorial7/tutorial.py
index bf5b55d9b..2e6f772c9 100644
--- a/tutorials/tutorial7/tutorial.py
+++ b/tutorials/tutorial7/tutorial.py
@@ -2,15 +2,15 @@
# coding: utf-8
# # Tutorial: Inverse Problem Solving with Physics-Informed Neural Network
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial7/tutorial.ipynb)
-#
+#
# ## Introduction to the Inverse Problem
-#
+#
# This tutorial demonstrates how to solve an inverse Poisson problem using Physics-Informed Neural Networks (PINNs).
-#
+#
# The problem is defined as a Poisson equation with homogeneous boundary conditions:
-#
+#
# \begin{equation}
# \begin{cases}
# \Delta u = e^{-2(x - \mu_1)^2 - 2(y - \mu_2)^2} \quad \text{in } \Omega, \\
@@ -18,18 +18,18 @@
# u(\mu_1, \mu_2) = \text{data}
# \end{cases}
# \end{equation}
-#
+#
# Here, $\Omega$ is the square domain $[-2, 2] \times [-2, 2]$, and $\partial \Omega = \Gamma_1 \cup \Gamma_2 \cup \Gamma_3 \cup \Gamma_4$ represents the union of its boundaries.
-#
+#
# This type of setup defines an *inverse problem*, which has two primary objectives:
-#
+#
# - **Find the solution** $u$ that satisfies the Poisson equation,
# - **Identify the unknown parameters** $(\mu_1, \mu_2)$ that best fit the given data (as described by the third equation in the system).
-#
+#
# To tackle both objectives, we will define an `InverseProblem` using **PINA**.
-#
+#
# Let's begin with the necessary imports:
-#
+#
# In[1]:
@@ -45,8 +45,12 @@
get_ipython().system('pip install "pina-mathlab[tutorial]"')
# get the data
get_ipython().system('mkdir "data"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial7/data/pinn_solution_0.5_0.5" -O "data/pinn_solution_0.5_0.5"')
- get_ipython().system('wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial7/data/pts_0.5_0.5" -O "data/pts_0.5_0.5"')
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial7/data/pinn_solution_0.5_0.5" -O "data/pinn_solution_0.5_0.5"'
+ )
+ get_ipython().system(
+ 'wget "https://github.com/mathLab/PINA/raw/refs/heads/master/tutorials/tutorial7/data/pts_0.5_0.5" -O "data/pts_0.5_0.5"'
+ )
import matplotlib.pyplot as plt
import torch
@@ -68,14 +72,14 @@
seed_everything(883)
-# Next, we import the pre-saved data corresponding to the true parameter values $(\mu_1, \mu_2) = (0.5, 0.5)$.
+# Next, we import the pre-saved data corresponding to the true parameter values $(\mu_1, \mu_2) = (0.5, 0.5)$.
# These values represent the *optimal parameters* that we aim to recover through neural network training.
-#
+#
# In particular, we load:
-#
+#
# - `input` points — the spatial coordinates where observations are available,
# - `target` points — the corresponding $u$ values (i.e., the solution evaluated at the `input` points).
-#
+#
# This data will be used to guide the inverse problem and supervise the network’s prediction of the unknown parameters.
# In[2]:
@@ -88,10 +92,10 @@
# Next, let's visualize the data:
-#
+#
# - We'll plot the data points, i.e., the spatial coordinates where measurements are available.
# - We'll also display the reference solution corresponding to $(\mu_1, \mu_2) = (0.5, 0.5)$.
-#
+#
# This serves as the ground truth or expected output that our neural network should learn to approximate through training.
# In[3]:
@@ -107,10 +111,10 @@
# ## Inverse Problem Definition in PINA
-#
-# Next, we initialize the Poisson problem, which inherits from the `SpatialProblem` and `InverseProblem` classes.
+#
+# Next, we initialize the Poisson problem, which inherits from the `SpatialProblem` and `InverseProblem` classes.
# In this step, we need to define all the variables and specify the domain in which our unknown parameters $(\mu_1, \mu_2)$ reside.
-#
+#
# Note that the Laplace equation also takes these unknown parameters as inputs. These parameters will be treated as variables that the neural network will optimize during the training process, enabling it to learn the optimal values for $(\mu_1, \mu_2)$.
# In[4]:
@@ -179,11 +183,11 @@ class Poisson(SpatialProblem, InverseProblem):
problem.discretise_domain(1000, "random", domains="boundary")
-# Here, we define a simple callback for the trainer. This callback is used to save the parameters predicted by the neural network during training.
+# Here, we define a simple callback for the trainer. This callback is used to save the parameters predicted by the neural network during training.
# The parameters are saved every 100 epochs as `torch` tensors in a specified directory (in our case, `tutorial_logs`).
-#
+#
# The goal of this setup is to read the saved parameters after training and visualize their trend across the epochs. This allows us to monitor how the predicted parameters evolve throughout the training process.
-#
+#
# In[7]:
@@ -256,13 +260,13 @@ def on_train_epoch_end(self, trainer, __):
# ## What's Next?
-#
+#
# We have covered the basic usage of PINNs for inverse problem modeling. Here are some possible directions for further exploration:
-#
+#
# 1. **Experiment with different Physics-Informed strategies**: Explore variations in PINN training techniques to improve performance or tackle different types of problems.
-#
+#
# 2. **Apply to more complex problems**: Scale the approach to higher-dimensional or time-dependent inverse problems.
-#
+#
# 3. **...and many more!**: The possibilities are endless, from integrating additional physical constraints to testing on real-world datasets.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).
diff --git a/tutorials/tutorial8/tutorial.ipynb b/tutorials/tutorial8/tutorial.ipynb
index 015d3b288..1d2f9dc3e 100644
--- a/tutorials/tutorial8/tutorial.ipynb
+++ b/tutorials/tutorial8/tutorial.ipynb
@@ -196,7 +196,7 @@
"# fit the pod basis\n",
"trainer.data_module.setup(\"fit\") # set up the dataset\n",
"train_data = trainer.data_module.train_datasets[\"data\"].get_all_data()\n",
- "x_train = train_data.target # extract data for training\n",
+ "x_train = train_data.target # extract data for training\n",
"pod_nn.fit_pod(x=x_train)\n",
"\n",
"# now train\n",
diff --git a/tutorials/tutorial8/tutorial.py b/tutorials/tutorial8/tutorial.py
index f20157d67..659a52cde 100644
--- a/tutorials/tutorial8/tutorial.py
+++ b/tutorials/tutorial8/tutorial.py
@@ -2,13 +2,13 @@
# coding: utf-8
# # Tutorial: Reduced Order Modeling with POD-RBF and POD-NN Approaches for Fluid Dynamics
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial8/tutorial.ipynb)
# The goal of this tutorial is to demonstrate how to use the **PINA** library to apply a reduced-order modeling technique, as outlined in [1]. These methods share several similarities with machine learning approaches, as they focus on predicting the solution to differential equations, often parametric PDEs, in real-time.
-#
+#
# In particular, we will utilize **Proper Orthogonal Decomposition** (POD) in combination with two different regression techniques: **Radial Basis Function Interpolation** (POD-RBF) and **Neural Networks**(POD-NN) [2]. This process involves reducing the dimensionality of the parametric solution manifold through POD and then approximating it in the reduced space using a regression model (either a neural network or an RBF interpolation). In this example, we'll use a simple multilayer perceptron (MLP) as the regression model, but various architectures can be easily substituted.
-#
+#
# Let's start with the necessary imports.
# In[1]:
@@ -42,9 +42,9 @@
# We utilize the [Smithers](https://github.com/mathLab/Smithers) library to gather the parametric snapshots. Specifically, we use the `NavierStokesDataset` class, which contains a collection of parametric solutions to the Navier-Stokes equations in a 2D L-shaped domain. The parameter in this case is the inflow velocity.
-#
+#
# The dataset comprises 500 snapshots of the velocity fields (along the $x$, $y$ axes, and the magnitude), as well as the pressure fields, along with their corresponding parameter values.
-#
+#
# To visually inspect the snapshots, let's also plot the data points alongside the reference solution. This reference solution represents the expected output of our model.
# In[2]:
@@ -61,7 +61,7 @@
# The *snapshots*—i.e., the numerical solutions computed for several parameters—and the corresponding parameters are the only data we need to train the model, enabling us to predict the solution for any new test parameter. To properly validate the accuracy, we will split the 500 snapshots into the training dataset (90% of the original data) and the testing dataset (the remaining 10%) inside the `Trainer`.
-#
+#
# It is now time to define the problem!
# In[3]:
@@ -73,7 +73,7 @@
# We can then build a `POD-NN` model (using an MLP architecture as approximation) and compare it with a `POD-RBF` model (using a Radial Basis Function interpolation as approximation).
-#
+#
# ## POD-NN reduced order model
# Let's build the `PODNN` class
@@ -163,7 +163,7 @@ def fit_pod(self, x):
# ## POD-RBF Reduced Order Model
-#
+#
# Next, we define the model we want to use, incorporating the `PODBlock` and `RBFBlock` objects.
# In[8]:
@@ -210,9 +210,9 @@ def fit(self, p, x):
# ## POD-RBF vs POD-NN
-#
+#
# We can compare the solutions predicted by the `POD-RBF` and the `POD-NN` models with the original reference solution. By plotting these predicted solutions against the true solution, we can observe how each model performs.
-#
+#
# ### Observations:
# - **POD-RBF**: The solution predicted by the `POD-RBF` model typically offers a smooth approximation for the parametric solution, as RBF interpolation is well-suited for capturing smooth variations.
# - **POD-NN**: The `POD-NN` model, while more flexible due to the neural network architecture, may show some discrepancies—especially for low velocities or in regions where the training data is sparse. However, with longer training times and adjustments in the network architecture, we can improve the predictions.
@@ -274,21 +274,21 @@ def fit(self, p, x):
# ## What's Next?
-#
+#
# Congratulations on completing this tutorial using **PINA** to apply reduced order modeling techniques with **POD-RBF** and **POD-NN**! There are several directions you can explore next:
-#
+#
# 1. **Extend to More Complex Problems**: Try using more complex parametric domains or PDEs. For example, you can explore Navier-Stokes equations in 3D or more complex boundary conditions.
-#
+#
# 2. **Combine POD with Deep Learning Techniques**: Investigate hybrid methods, such as combining **POD-NN** with convolutional layers or recurrent layers, to handle time-dependent problems or more complex spatial dependencies.
-#
+#
# 3. **Evaluate Performance on Larger Datasets**: Work with larger datasets to assess how well these methods scale. You may want to test on datasets from simulations or real-world problems.
-#
+#
# 4. **Hybrid Models with Physics Informed Networks (PINN)**: Integrate **POD** models with PINN frameworks to include physics-based regularization in your model and improve predictions for more complex scenarios, such as turbulent fluid flow.
-#
+#
# 5. **...and many more!**: The potential applications of reduced order models are vast, ranging from material science simulations to real-time predictions in engineering applications.
-#
+#
# For more information and advanced tutorials, refer to the [PINA Documentation](https://mathlab.github.io/PINA/).
-#
+#
# ### References
-# 1. Rozza G., Stabile G., Ballarin F. (2022). Advanced Reduced Order Methods and Applications in Computational Fluid Dynamics, Society for Industrial and Applied Mathematics.
+# 1. Rozza G., Stabile G., Ballarin F. (2022). Advanced Reduced Order Methods and Applications in Computational Fluid Dynamics, Society for Industrial and Applied Mathematics.
# 2. Hesthaven, J. S., & Ubbiali, S. (2018). Non-intrusive reduced order modeling of nonlinear problems using neural networks. Journal of Computational Physics, 363, 55-78.
diff --git a/tutorials/tutorial9/tutorial.ipynb b/tutorials/tutorial9/tutorial.ipynb
index 845d649ff..a23ed1abb 100644
--- a/tutorials/tutorial9/tutorial.ipynb
+++ b/tutorials/tutorial9/tutorial.ipynb
@@ -94,7 +94,9 @@
" return -6.0 * pi**2 * torch.sin(3 * pi * x) * torch.cos(pi * x)\n",
"\n",
"\n",
- "helmholtz_equation = HelmholtzEquation(k=10 * torch.pi**2, forcing_term=forcing_term)\n",
+ "helmholtz_equation = HelmholtzEquation(\n",
+ " k=10 * torch.pi**2, forcing_term=forcing_term\n",
+ ")\n",
"\n",
"\n",
"class Helmholtz(SpatialProblem):\n",
diff --git a/tutorials/tutorial9/tutorial.py b/tutorials/tutorial9/tutorial.py
index 4f5809826..b7f2a997c 100644
--- a/tutorials/tutorial9/tutorial.py
+++ b/tutorials/tutorial9/tutorial.py
@@ -2,14 +2,14 @@
# coding: utf-8
# # Tutorial: Applying Periodic Boundary Conditions in PINNs to solve the Helmholtz Problem
-#
+#
# [](https://colab.research.google.com/github/mathLab/PINA/blob/master/tutorials/tutorial9/tutorial.ipynb)
-#
-# This tutorial demonstrates how to solve a one-dimensional Helmholtz equation with periodic boundary conditions (PBC) using Physics-Informed Neural Networks (PINNs).
+#
+# This tutorial demonstrates how to solve a one-dimensional Helmholtz equation with periodic boundary conditions (PBC) using Physics-Informed Neural Networks (PINNs).
# We will use standard PINN training, augmented with a periodic input expansion as introduced in [*An Expert’s Guide to Training Physics-Informed Neural Networks*](https://arxiv.org/abs/2308.08468).
-#
+#
# Let's start with some useful imports:
-#
+#
# In[ ]:
@@ -41,33 +41,33 @@
# ## Problem Definition
-#
+#
# The one-dimensional Helmholtz problem is mathematically expressed as:
-#
+#
# $$
# \begin{cases}
# \frac{d^2}{dx^2}u(x) - \lambda u(x) - f(x) &= 0 \quad \text{for } x \in (0, 2) \\
# u^{(m)}(x = 0) - u^{(m)}(x = 2) &= 0 \quad \text{for } m \in \{0, 1, \dots\}
# \end{cases}
# $$
-#
-# In this case, we seek a solution that is $C^{\infty}$ (infinitely differentiable) and periodic with period 2, over the infinite domain $x \in (-\infty, \infty)$.
-#
+#
+# In this case, we seek a solution that is $C^{\infty}$ (infinitely differentiable) and periodic with period 2, over the infinite domain $x \in (-\infty, \infty)$.
+#
# A classical PINN approach would require enforcing periodic boundary conditions (PBC) for all derivatives—an infinite set of constraints—which is clearly infeasible.
-#
+#
# To address this, we adopt a strategy known as *coordinate augmentation*. In this approach, we apply a coordinate transformation $v(x)$ such that the transformed inputs naturally satisfy the periodicity condition:
-#
+#
# $$
# u^{(m)}(x = 0) - u^{(m)}(x = 2) = 0 \quad \text{for } m \in \{0, 1, \dots\}
# $$
-#
+#
# For demonstration purposes, we choose the specific parameters:
-#
+#
# - $\lambda = -10\pi^2$
# - $f(x) = -6\pi^2 \sin(3\pi x) \cos(\pi x)$
-#
+#
# These yield an analytical solution:
-#
+#
# $$
# u(x) = \sin(\pi x) \cos(3\pi x)
# $$
@@ -105,39 +105,39 @@ def solution(self, pts):
# As usual, the Helmholtz problem is implemented in **PINA** as a class. The governing equations are defined as `conditions`, which must be satisfied within their respective domains. The `solution` represents the exact analytical solution, which will be used to evaluate the accuracy of the predicted solution.
-#
-# For selecting collocation points, we use Latin Hypercube Sampling (LHS), a common strategy for efficient space-filling in high-dimensional domains
-#
+#
+# For selecting collocation points, we use Latin Hypercube Sampling (LHS), a common strategy for efficient space-filling in high-dimensional domains
+#
# ## Solving the Problem with a Periodic Network
-#
-# Any $\mathcal{C}^{\infty}$ periodic function $u : \mathbb{R} \rightarrow \mathbb{R}$ with period $L \in \mathbb{N}$
+#
+# Any $\mathcal{C}^{\infty}$ periodic function $u : \mathbb{R} \rightarrow \mathbb{R}$ with period $L \in \mathbb{N}$
# can be constructed by composing an arbitrary smooth function $f : \mathbb{R}^n \rightarrow \mathbb{R}$ with a smooth, periodic mapping$v : \mathbb{R} \rightarrow \mathbb{R}^n$ of the same period $L$. That is,
-#
+#
# $$
# u(x) = f(v(x)).
# $$
-#
-# This formulation is general and can be extended to arbitrary dimensions.
+#
+# This formulation is general and can be extended to arbitrary dimensions.
# For more details, see [*A Method for Representing Periodic Functions and Enforcing Exactly Periodic Boundary Conditions with Deep Neural Networks*](https://arxiv.org/pdf/2007.07442).
-#
+#
# In our specific case, we define the periodic embedding as:
-#
+#
# $$
# v(x) = \left[1, \cos\left(\frac{2\pi}{L} x\right), \sin\left(\frac{2\pi}{L} x\right)\right],
# $$
-#
+#
# which constitutes the coordinate augmentation. The function $f(\cdot)$ is approximated by a neural network $NN_{\theta}(\cdot)$, resulting in the approximate PINN solution:
-#
+#
# $$
# u(x) \approx u_{\theta}(x) = NN_{\theta}(v(x)).
# $$
-#
-# In **PINA**, this is implemented using the `PeriodicBoundaryEmbedding` layer for $v(x)$,
-# paired with any `pina.model` to define the neural network $NN_{\theta}$.
-#
+#
+# In **PINA**, this is implemented using the `PeriodicBoundaryEmbedding` layer for $v(x)$,
+# paired with any `pina.model` to define the neural network $NN_{\theta}$.
+#
# Let’s see how this is put into practice!
-#
-#
+#
+#
# In[3]:
@@ -154,11 +154,11 @@ def solution(self, pts):
# As simple as that!
-#
-# In higher dimensions, you can specify different periods for each coordinate using a dictionary.
-# For example, `periods = {'x': 2, 'y': 3, ...}` indicates a periodicity of 2 in the $x$ direction,
+#
+# In higher dimensions, you can specify different periods for each coordinate using a dictionary.
+# For example, `periods = {'x': 2, 'y': 3, ...}` indicates a periodicity of 2 in the $x$ direction,
# 3 in the $y$ direction, and so on.
-#
+#
# We will now solve the problem using the usual `PINN` and `Trainer` classes. After training, we'll examine the losses using the `MetricTracker` callback from `pina.callback`.
# In[ ]:
@@ -234,15 +234,15 @@ def solution(self, pts):
# It's clear that the network successfully captures the periodicity of the solution, with the error also exhibiting a periodic pattern. Naturally, training for a longer duration or using a more expressive neural network could further improve the results.
# ## What's next?
-#
+#
# Congratulations on completing the one-dimensional Helmholtz tutorial with **PINA**! Here are a few directions you can explore next:
-#
+#
# 1. **Train longer or with different architectures**: Experiment with extended training or modify the network's depth and width to evaluate improvements in accuracy.
-#
+#
# 2. **Apply `PeriodicBoundaryEmbedding` to time-dependent problems**: Explore more complex scenarios such as spatiotemporal PDEs (see the official documentation for examples).
-#
+#
# 3. **Try extra feature training**: Integrate additional physical or domain-specific features to guide the learning process more effectively.
-#
+#
# 4. **...and many more!**: Extend to higher dimensions, test on other PDEs, or even develop custom embeddings tailored to your problem.
-#
+#
# For more resources and tutorials, check out the [PINA Documentation](https://mathlab.github.io/PINA/).